
The Meaning Layer for Unstructured Data: Why the Next Decade Belongs Upstream
Over the last decade, the modern data stack has centered itself around the warehouse. The warehouse became the gravitational center for analytics, BI, and increasingly ML. But something interesting is happening—and the recent dbt + Fivetran merger put a spotlight on it:
Power is shifting upstream.
Upstream is where data movement and meaning are defined.
Upstream is where the semantics, the business logic, and the true shape of data are created.
Upstream is where context—once scattered or implicit—gets encoded into systems.
And upstream is where unstructured data, the largest and fastest-growing class of enterprise data, still has no meaning layer at all.
The warehouse is no longer where the value is created.
It’s where value is stored.
For structured data, the semantic layer tried to fill the gap.
But for unstructured data—customer conversations, sales calls, support chats, surveys, notes, emails, transcripts, voice interactions—there is no equivalent layer that defines meaning, ensures consistency, or generates reusable logic.
As unstructured data becomes core to operations, that gap becomes a competitive bottleneck.
This article lays out why:
the semantic layer is struggling
upstream transformation is finally becoming the locus of value
unstructured data is the biggest blind spot in the stack
and why the future requires a Meaning Layer for Unstructured Data
1. The Semantic Layer Isn't Dead—But It’s Far From What We Need
A recent viral LinkedIn post from Kenny Ning highlighted something the industry has whispered for years:
Semantic layers haven’t delivered on their promise.
He’s not wrong—but also not for the reasons most think.
The problem is not that semantic layers don’t create value. They do.
The problem is where they live and what they assume.
Semantic layers were designed for structured data, where:
schemas are known
tables are stable
metrics can be cleanly defined
joins, relationships, and dimensions are explicitly modeled
In other words: semantic layers work when meaning already exists.
They simply “codify” it.
But in today’s world, meaning is increasingly generated, inferred, contextual, and dynamic.
It is shaped by language, intent, and behavior—none of which live in your warehouse tables.
The semantic layer assumed the lowest common denominator of structure.
It never considered the complexity and richness of unstructured data.
So semantic layers are not failing—they are bound to a shrinking fraction of enterprise data.
This mismatch is why we see:
metric layers constantly breaking
inconsistent logic between tools
BI dashboards drifting from operational reality
teams reinventing the same definitions
“semantics” being brittle and fragile
Semantic layers weren’t the wrong idea.
They were simply built for a world that no longer exists.
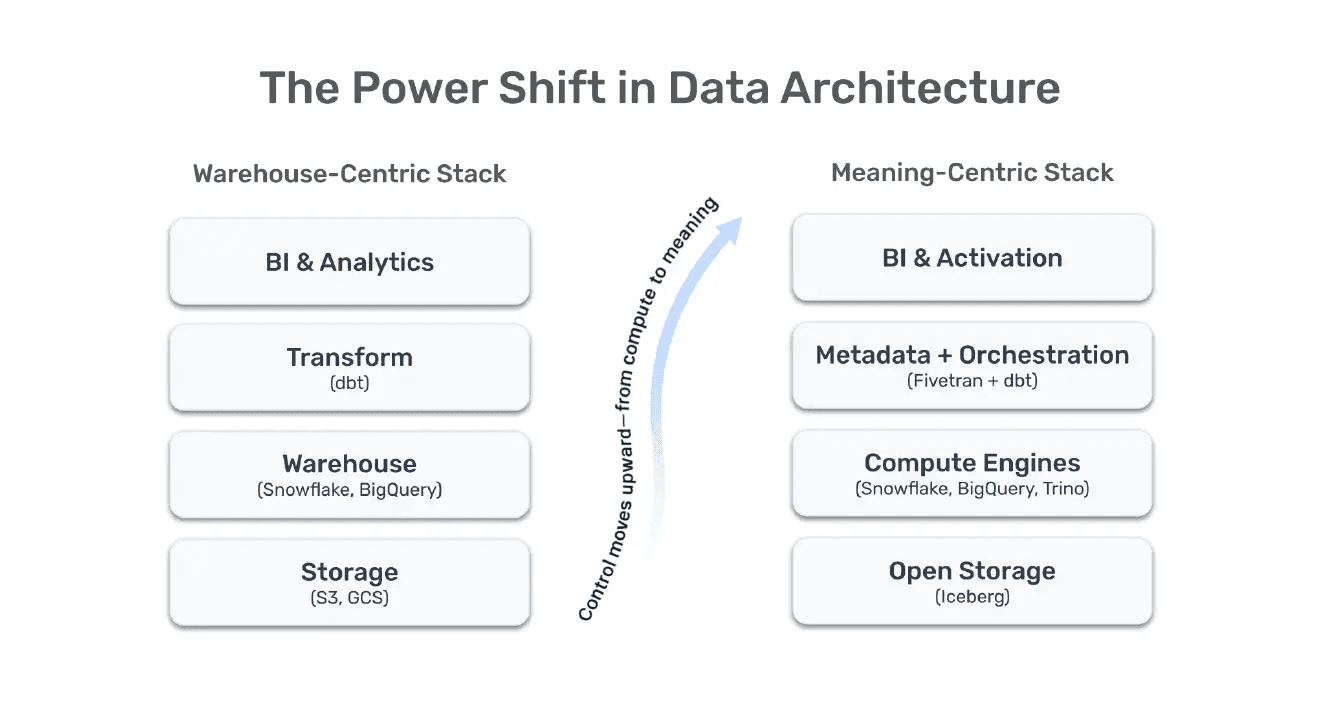
2. The Fivetran + dbt Merger Signals a Power Shift: Meaning Moves Upstream
Constance Martineau’s (Product Leader at Astronomer) analysis of the dbt/Fivetran merger hit on a profound point:
Power is shifting upstream into ingestion and transformation.
Historically, data moved like this:
In the past the warehouse defined the shape of every data stack.
Meaning was applied after the fact.
It was downstream, brittle, and disconnected.
But the modern reality is different:
🟥 Value is created upstream, not downstream.
Why?
Because upstream is where the critical questions are answered:
What does this event actually mean?
How should this conversation be interpreted?
What logic, transformations, or classifications define the business?
How should ambiguous, narrative, or qualitative signals be structured?
Once logic moves upstream…
transformations become reusable
models become consistent
lineage becomes reliable
and analytics becomes far easier downstream
The warehouse is becoming a passive substrate.
The action is happening before data ever lands there.
But this shift exposes a glaring hole in modern data architecture:
✔️ We have transformation engines for structured data
❌ but we have no transformation engine for unstructured data.
We have dbt, SQL, and metric layers for tables.
But for language, conversations, free-form text?
We have nothing equivalent.
3. The Largest Data Source in the Enterprise Has Zero Semantics
Every company today is drowning in unstructured data:
support interactions
customer chats
sales conversations
call transcripts
surveys and open-ends
user reviews
email threads
field notes
chatbot logs
agent messages
This data contains the richest signal about customer expectations, product weaknesses, churn risks, unmet needs, friction points, and emerging opportunities.
Yet it lacks everything structured data takes for granted:
no schema
no modeling conventions
no standard transformations
no metric layer
no semantic governance
no lineage
no shared definitions
no versioning
no upstream logic
Every company reinvents the wheel: new prompts, new tags, new dashboards, new classifications—each one a one-off.
It’s an ecosystem without Meaning Infrastructure.
Without standards.
Without shared logic.
Without the equivalent of dbt, LookML, or any modern transformation layer.
In other words, unstructured data is the most valuable data—and the least treated as data.
This is precisely the gap the industry must address next.
4. What the Industry Actually Needs: A Meaning Layer for Unstructured Data
If structured data had its revolution—metric layers, transformation tooling, SQL standards—unstructured data is now overdue for its own.
The solution is a new class of system:
The Meaning Layer for Unstructured Data supported by..
Meaning Infrastructure and operationalized through..
Meaning Orchestration.
This isn’t text analytics.
This isn’t classification.
This isn’t sentiment scoring or topic extraction.
This is infrastructure that acts as the semantic foundation for all unstructured data.
A Meaning Layer is not an add-on to the stack. It becomes the new center of gravity once you recognize that unstructured data cannot participate in BI, governance, or AI without shared semantics. At that point the challenge is no longer “extracting insights.” It becomes defining the common interpretation of language so every downstream system is operating on the same reality.
That requires more than NLP. It requires an infrastructure layer that turns text into something durable, governed, and computable. It has to formalize how meaning is defined, how context is encoded, and how those decisions propagate through the rest of the stack.
The checklist below outlines the non-negotiable capabilities of a real Meaning Layer and what it must deliver before unstructured data can behave like a first-class analytical asset:

This layer becomes the core semantic engine for the enterprise’s language data.
Without it, unstructured data will remain “unusable dark matter.”
With it, unstructured data becomes “operational intelligence.”
A Meaning Layer is to unstructured data what:
dbt is to transformations
Fivetran is to ingestion
the semantic layer is to structured metrics
reverse ETL was to activation
It’s the missing foundational layer.
5. Why This Layer Must Live Upstream
Just as the dbt/Fivetran merger highlights, meaning must be defined before data reaches the warehouse—not after.
Why?
Because meaning is part of the data lineage.
Therefore, meaning has to be defined before the warehouse.
Once unstructured data enters the stack, every downstream tool inherits whatever semantics you set upstream. If you skip that step, models disagree, dashboards drift, and analysis becomes guesswork.
Define meaning upstream and the opposite happens. Structure is created once, logic stays consistent, and every downstream query becomes trivial. AI agents finally have something solid to stand on.

If meaning is defined downstream, every tool interprets differently.
If meaning is defined upstream, every tool benefits from semantic stability.
This is why Meaning Infrastructure must sit at the ingestion + transformation boundary—the same place where the modern data stack just shifted its center of gravity.
Upstream is where dbt won.
Upstream is where Fivetran moved.
And upstream is exactly where the Meaning Layer for Unstructured Data must live.
6. Meaning Infrastructure Is the Foundation for Agentic Workflows
AI agents, orchestrators, and knowledge-graph-driven systems are exploding across the enterprise. But there’s a catch:
Agents cannot operate on raw text.
Knowledge graphs cannot ground themselves in unstructured chaos.
Automated workflows break when semantics drift.
Agents need structure. But more importantly—they need meaning. In our last article on How Knowledge Graphs and Agentic Workflows Are Reimagining Unstructured Data, we discussed how knowledge graphs and agentic workflows that sit on top of unstructured data transformed through a Meaning Layer could open up the possibilities for endless new automations and capabilities for different teams. But without a way to establish a Meaning Layer, organizations are left in the dark in terms of how to fully operationalize their unstructured customer data.

Meaning Infrastructure provides exactly that:
consistent semantic grounding
interpretation logic
event/context understanding
canonical dimensions
standardized signals
reliable reason extraction
It becomes the substrate upon which:
autonomous agents act
workflows self-correct
knowledge graphs stay fresh
customer intelligence becomes operational
predictive models become reliable
analytics becomes frictionless
This is why the Meaning Layer is not an analytics feature.
It is a foundation for the next era of intelligent enterprise systems.
7. The Future: A Unified Meaning Pipeline for Language Data
The next era of language data starts by moving meaning to the front of the pipeline.
The diagram illustrates this new path: raw text is interpreted upstream, transformed into stable dimensions, and only then handed off to the systems that depend on consistent semantics.
It’s a small change in order, but it reshapes the entire stack.
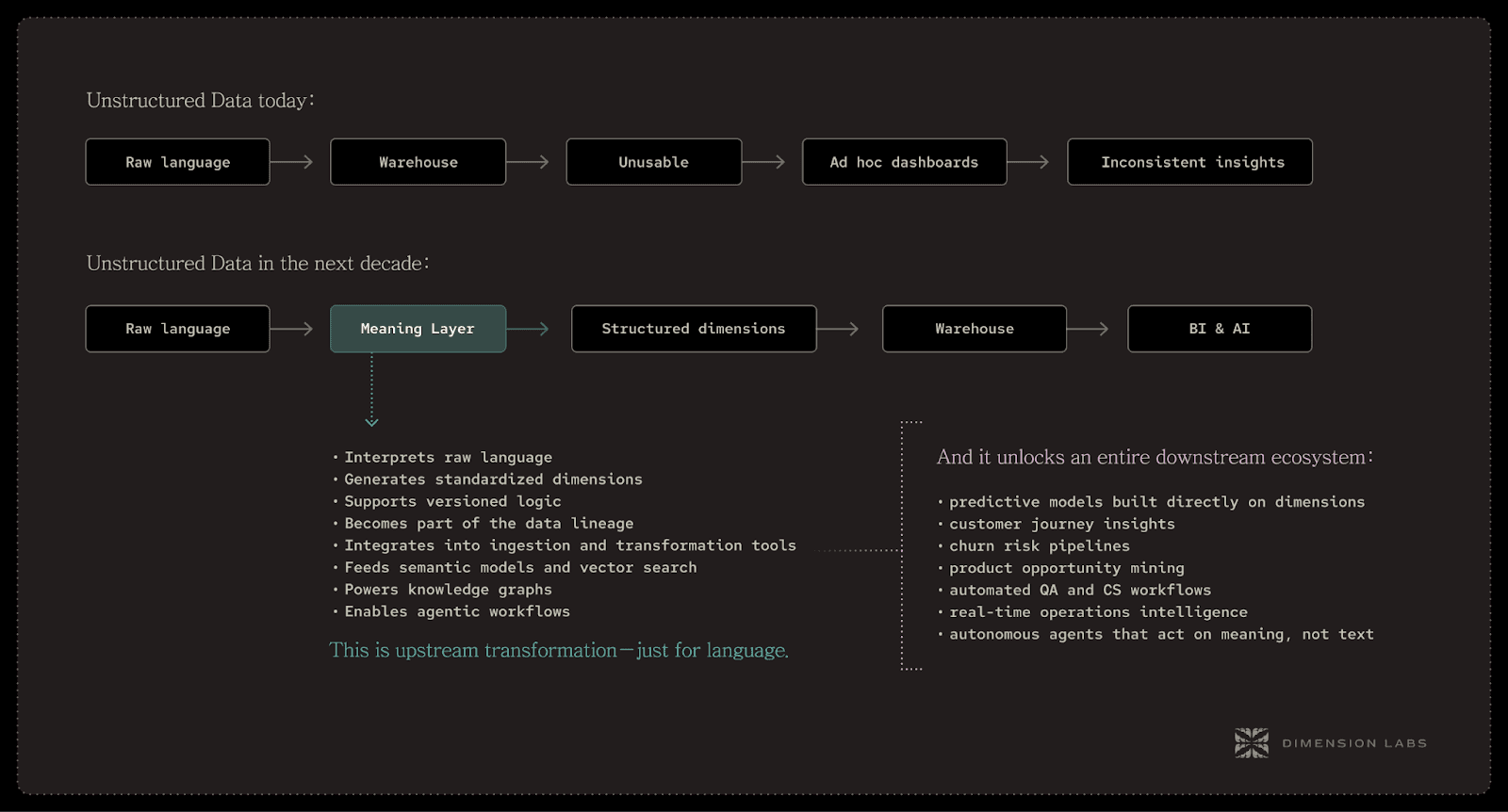
Once meaning is upstream, you stop doing “analysis,” and start doing: automated reasoning.
Automated reasoning means systems can synthesize signals across conversations, channels, and contexts without human stitching — producing conclusions that reflect the true state of the customer, not just isolated data points.
It’s the moment when unstructured data stops being something you analyze and becomes something your organization can act on automatically. And once that shift happens, the nature of the modern data stack (and where value is created) changes entirely.
8. The Takeaway: Meaning Is the Next Strategic Layer of the Enterprise
The Next Frontier of the Modern Data Stack Is Meaning
We are entering a world where:
metrics are commoditized
BI is commoditized
LLMs are commoditized
warehouses are commoditized
ingestion is commoditized
But meaning is not.
Meaning is the rarest and most valuable layer.
Meaning is where interpretation lives.
Meaning is where organizations differentiate.
Meaning is what powers every AI agent, every analytics workflow, every customer insight.
The modern data stack created massive leverage for structured data.
Now the opportunity is 100x larger, because unstructured data is 80%+ of what companies actually collect.
The companies who build a Meaning Layer—
and the companies who adopt one—
will own the next decade of data advantage.
Because in the end:
Structure lets you query data.
Meaning lets you use it.