
Beyond Sentiment and Categories: A New Era for Customer Insights
For decades, when companies thought about “text analytics,” two words came to mind: sentiment and categories. Was the customer happy or upset? Which bucket does their feedback fall into — “billing issue,” “product complaint,” “shipping delay”?
These were useful starting points. But let’s be honest: they’re the equivalent of looking at a painting in black-and-white when the full canvas is in color. If that’s all you believe is possible, then you’re missing the real opportunity. Because here’s the truth: unstructured language data is the richest, most predictive, and most human form of data your company has. And today, we finally have the technology and the infrastructure to decode it.
This article will break down:
Why sentiment and categories are no longer enough.
The full spectrum of insights hidden in unstructured data.
Case studies of how leading companies are already using these insights to compete.
What this means for the future of data teams — and why it will reshape the Modern Data Stack.
Why “Sentiment + Categories” Is a Dead-End
Text analytics was born in an era when tooling was primitive. You pointed keyword dictionaries or basic machine learning models at data, and you got outputs like:
Sentiment score: positive/negative/neutral
Category buckets: “shipping,” “support,” “billing”
This made dashboards look clean, but it had three fatal flaws:
1) It reduced complex human expression into over-simplified labels. A customer saying: “I’ve called three times, no one fixed this, I’m exhausted” is more than just “negative sentiment.” It’s churn risk, high effort, and a loyalty crisis.
2) It ignored predictive power. Buckets tell you what’s happening. They don’t tell you what’s likely to happen next.
3) It left value on the table. Instead of surfacing churn drivers, upsell signals, or systemic process failures, companies kept repeating the same insights: “shipping issues are up 12%.”
This reductionist mindset has conditioned an entire generation of executives to underestimate unstructured data.
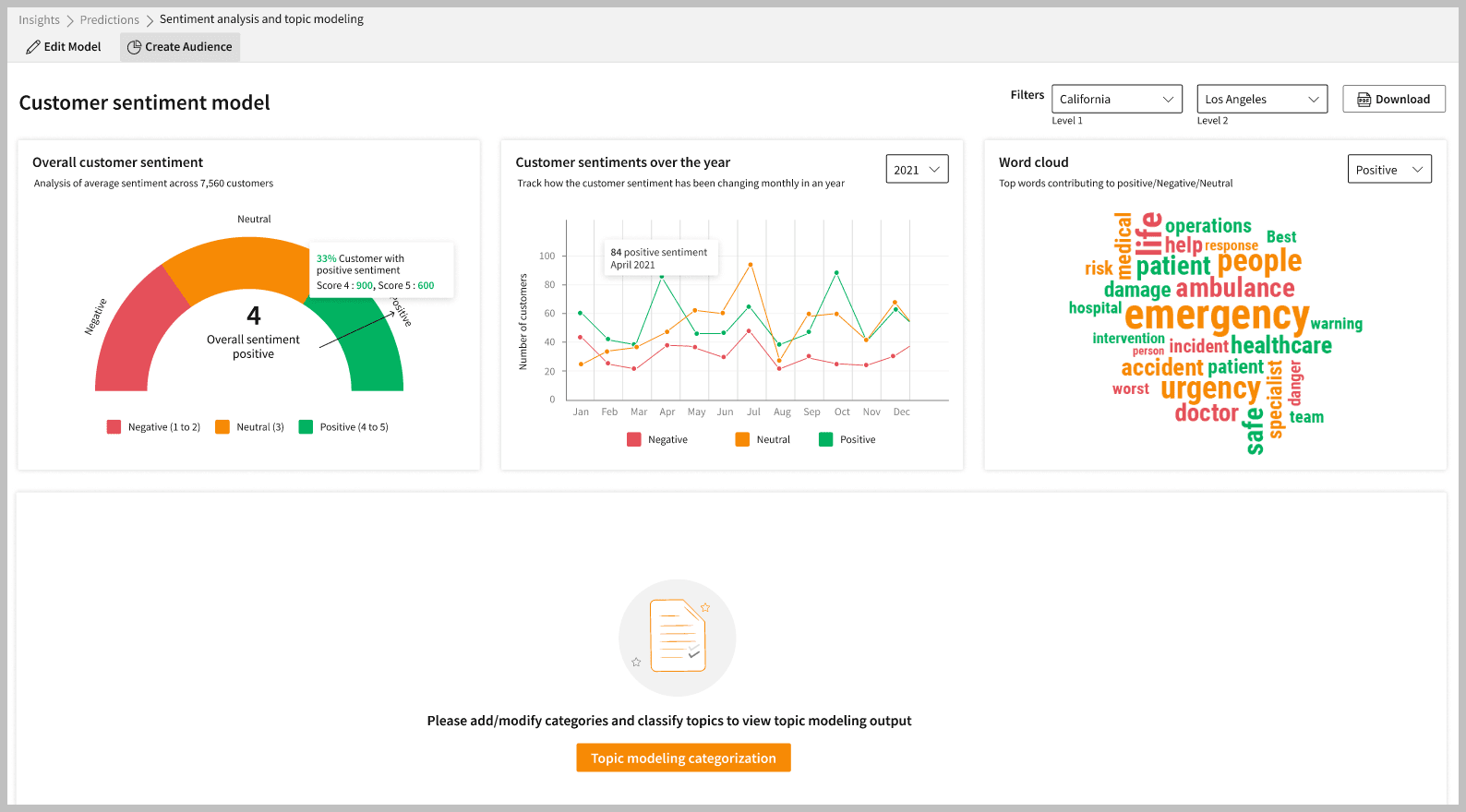
What’s Really Possible: The Full Spectrum of Unstructured Insights
Let’s reset the frame. Here’s what becomes possible when you stop thinking in “sentiment + categories” and start thinking in dimensions of insight.
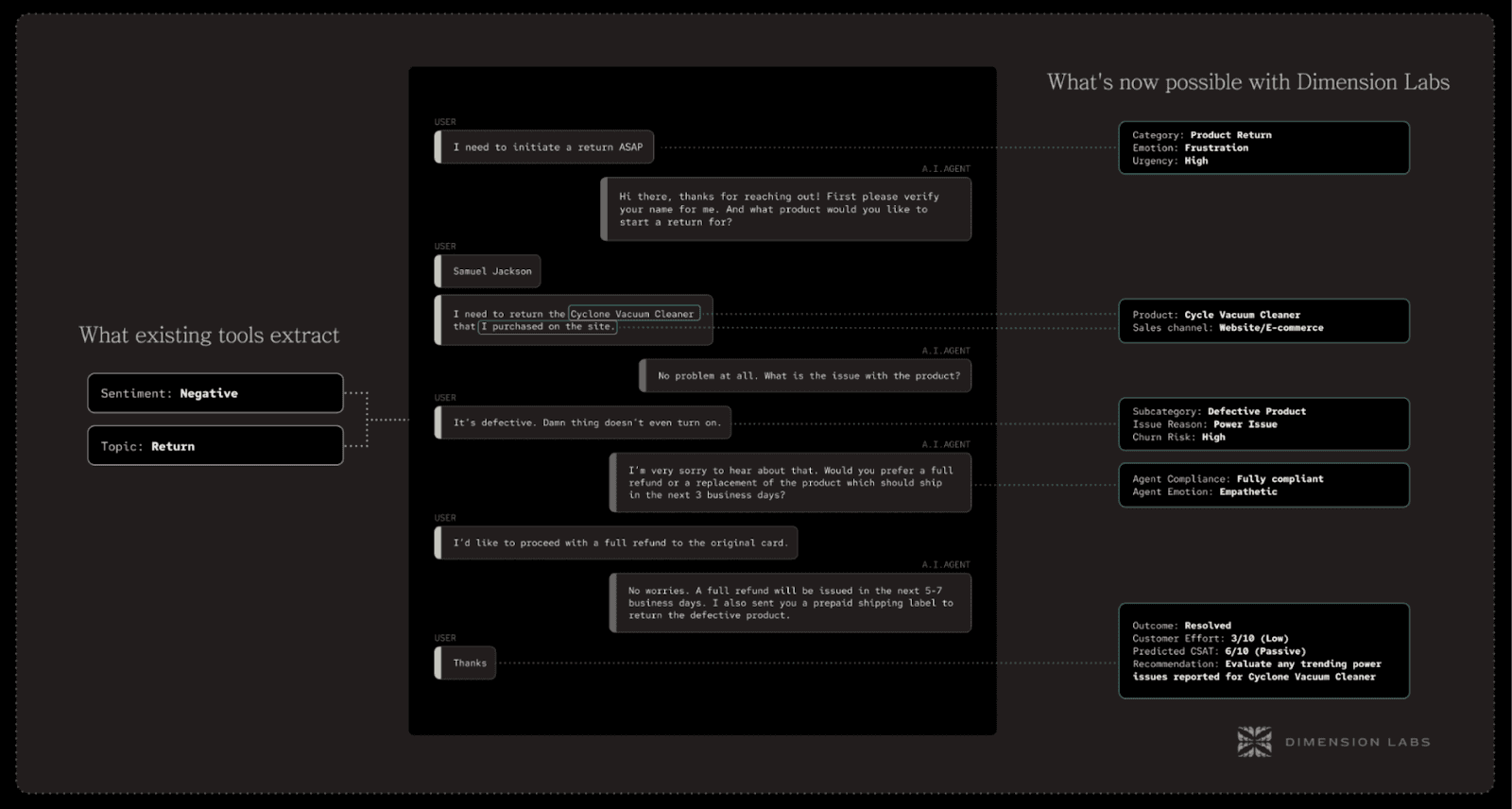
#1 — Churn Risk Prediction
Churn risk is one of the most powerful — and most underutilized — insights hidden in unstructured data. In structured dashboards, churn usually surfaces after the fact: when revenue drops, when accounts close, or when usage falls off a cliff. But the signals that a customer is on the verge of leaving are almost always visible earlier in their language.
Customers rarely say “we are canceling.” Instead, they reveal it in tone, frequency of complaints, and intent signals. Words like “again,” “still waiting,” “tired of this” are early indicators. Phrases like “we’re considering other vendors” or “maybe we’ll switch” are red flags. Even polite frustration, like “this is becoming a challenge for us,” is predictive.
Traditional sentiment analysis misses this completely. A “negative” tag doesn’t tell you if someone is mildly annoyed or days away from churning. Categories like “support issue” don’t capture the trajectory of risk.
With an unstructured data pipeline, you can build churn-risk dimensions that score customers in real time. Every chat, email, or call transcript becomes part of a risk profile. Data teams can flag accounts with rising churn probability and hand them to customer success before the exit happens.
Business impact:
CX teams can proactively reach out to save accounts.
Product teams can identify which features are causing dissatisfaction.
Executives can forecast retention more accurately.
Customer Story: A global SaaS provider implemented churn-risk tagging on all support chats. They identified 22% of accounts as “high churn risk” weeks before NPS surveys would have flagged them. Proactive outreach cut overall churn by 14% in one quarter.
#2 — Predicted CSAT & Effort Scores
CSAT and CES (Customer Effort Score) are gold-standard metrics — but they rely on surveys. The problem? Fewer than 10% of customers respond, and those who do are often polarized (extremely happy or extremely angry). That leaves most organizations flying blind.
Unstructured data provides a breakthrough: every interaction can be scored without asking. AI can predict satisfaction and effort from the language used, giving 100% coverage instead of single-digit survey response rates.
Think of the difference:
Surveys give you a handful of signals, often lagging.
Unstructured data scoring gives you millions of signals, in real time.
A customer who says “I’ve been transferred three times and still don’t have an answer” is clearly high-effort and low-satisfaction, even if they never fill out a survey. Another who says “Wow, that was faster than expected, thanks so much!” is clearly high CSAT.
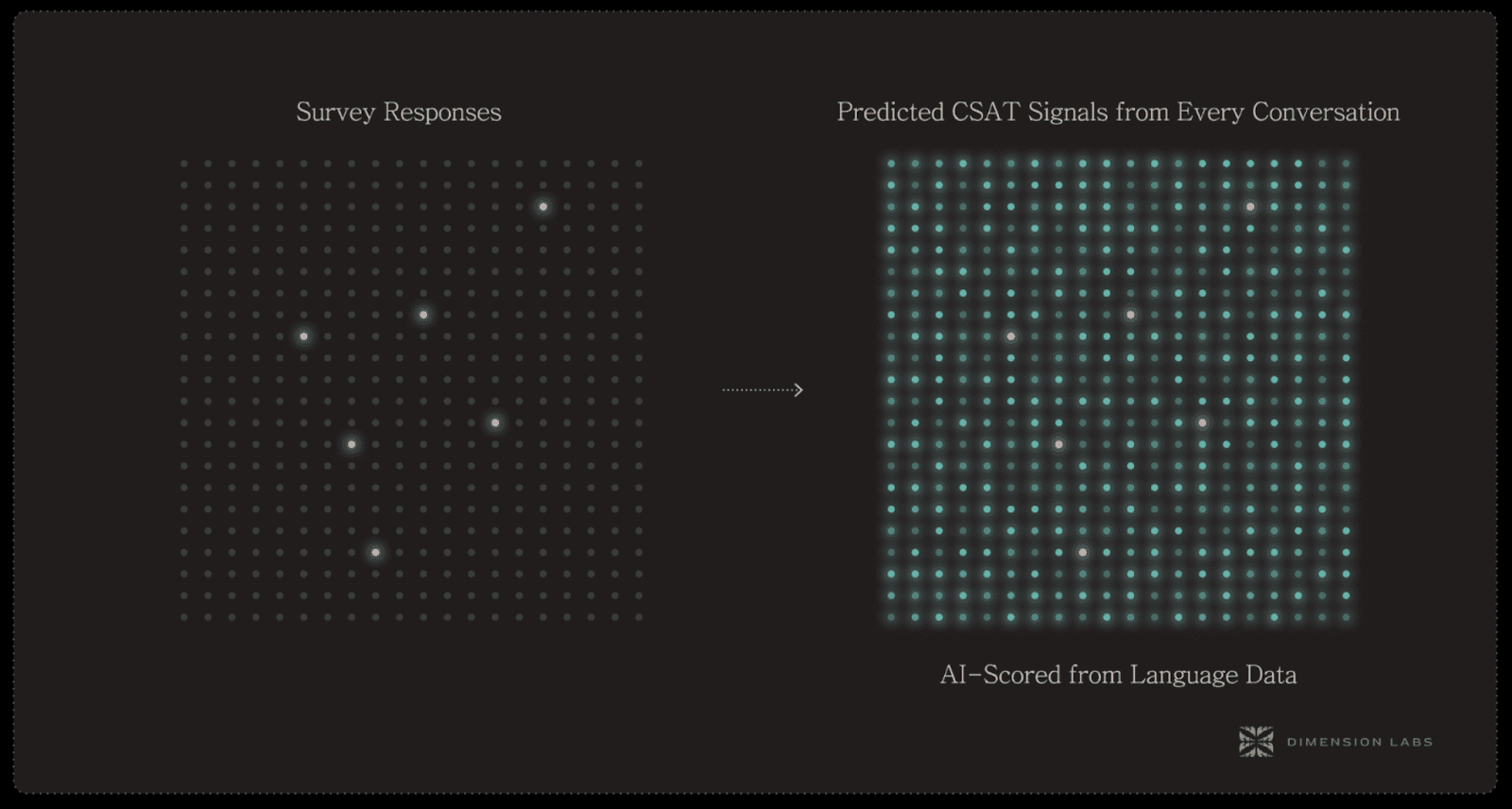
Business impact:
Contact centers can route predicted low-CSAT customers to senior agents in real time.
Ops leaders can identify which processes drive high effort and redesign them.
Executives get truer, fuller CSAT coverage for board reporting.
Customer Story: A Fortune 500 telco replaced post-call surveys with predicted CSAT scores across all calls. They discovered their IVR (phone menu) was dragging predicted CSAT down by 18 points — a problem surveys completely missed due to low response rates. Fixing it saved millions in customer retention.
#3 — Emerging Issue Detection
Every company has blind spots. The most dangerous ones are emerging issues: bugs, outages, broken policies, or unexpected failures. These problems appear first in conversations, but by the time they show up in structured data (complaint tickets, churn reports), it’s too late.
Traditional dashboards see symptoms, not causes. They’ll show a spike in “support calls,” but not that 40% of those calls are about the same new checkout error. Surveys are lagging indicators — customers complain weeks after the damage.
Unstructured data changes the game. By clustering and monitoring language, companies can detect anomalies in near real-time. When dozens of customers start mentioning “card not accepted” or “error 503,” it becomes visible as a new issue cluster.
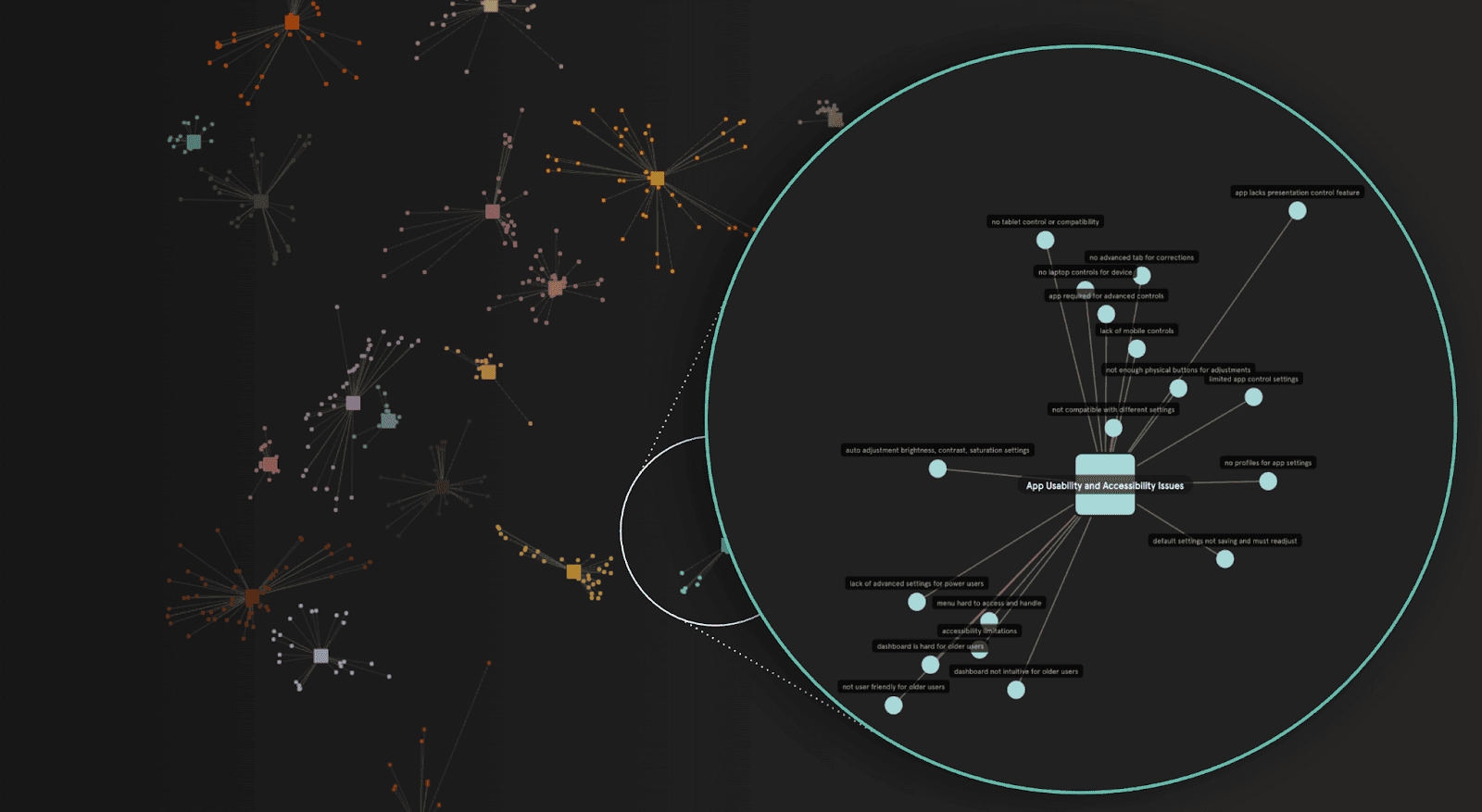
Business impact:
Engineering teams can catch bugs days earlier.
Ops teams can resolve systemic failures before they spread.
Executives can avoid PR disasters by acting before customers go public.
Customer Story: A global hotel brand integrated chat logs and online reviews. Within days, they spotted rising mentions of “check-in kiosk not working.” It was a hardware malfunction spreading across properties. Fixing it lifted guest satisfaction scores 12% — and prevented a potential social media storm.
#4 — Revenue and Upsell Signals
Support conversations aren’t just cost centers. They’re revenue signals — if you know how to look. Customers often reveal their growth, their intent, or their purchasing plans in passing.
“We’re hiring 50 more reps.”
“We’ll need more licenses.”
“Does this integrate with your premium plan?”
Traditional categorization throws these into “support” or “product questions,” burying them. But when mined systematically, these are direct sales triggers.
Business impact:
Sales teams can surface upsell opportunities directly from support channels.
Customer success can prioritize growth accounts.
Executives see revenue potential in what used to be noise.
Customer Story: A B2B SaaS platform mined its support chats and found hundreds of upsell signals that account managers never saw. In one quarter, it generated $2.7M in pipeline from “hidden” language data.
#5 — Agent Coaching and Process Intelligence
Unstructured data doesn’t just reflect customers — it reflects your people. Every conversation is a window into how agents handle requests: their tone, empathy, clarity, and adherence to process.
Sentiment dashboards don’t capture agent behavior. Categories don’t capture empathy. But unstructured analysis can. By measuring things like interrupt frequency, passive vs. active tone, or script adherence, companies can evaluate and coach agents objectively.
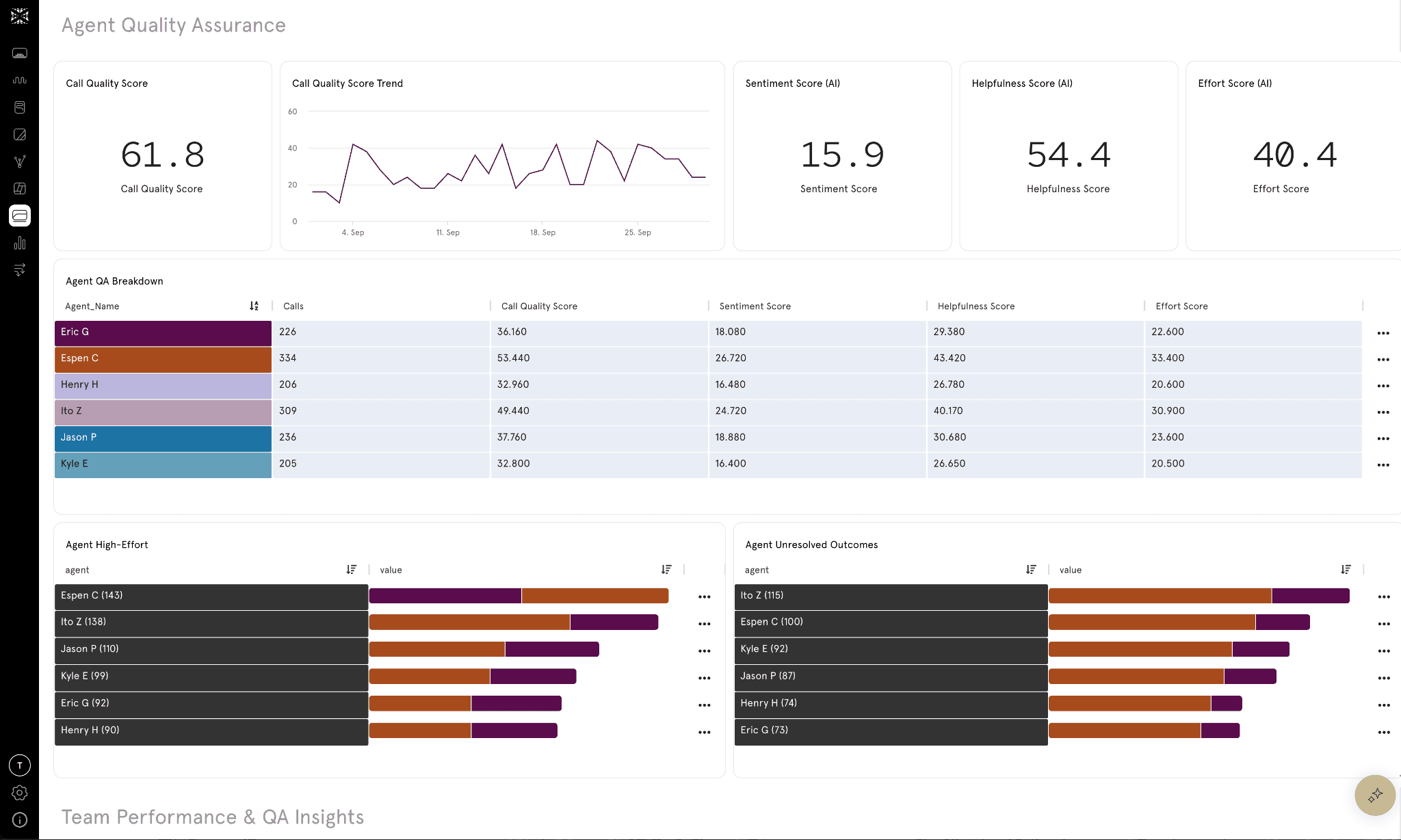
Business impact:
Training teams can design personalized coaching programs.
Ops leaders can identify bottlenecks (like agents who take twice as long).
Executives can ensure consistent brand voice at scale.
Customer Story: A financial services firm analyzed thousands of calls. They found one agent team had 25% longer handle times due to excessive confirmation steps. Coaching reduced handle time by 18% without hurting satisfaction.
#6 — Root Cause Analysis
“Shipping issue.” “Billing problem.” “Product complaint.” These are categories — but they aren’t causes. Root causes are the difference between knowing there’s a fire and knowing where it started.
Unstructured data allows for deeper clustering: not just “shipping,” but “late handoff from warehouse,” “carrier tracking failure,” or “address validation bug.” This level of granularity is impossible with simple ticket tags.
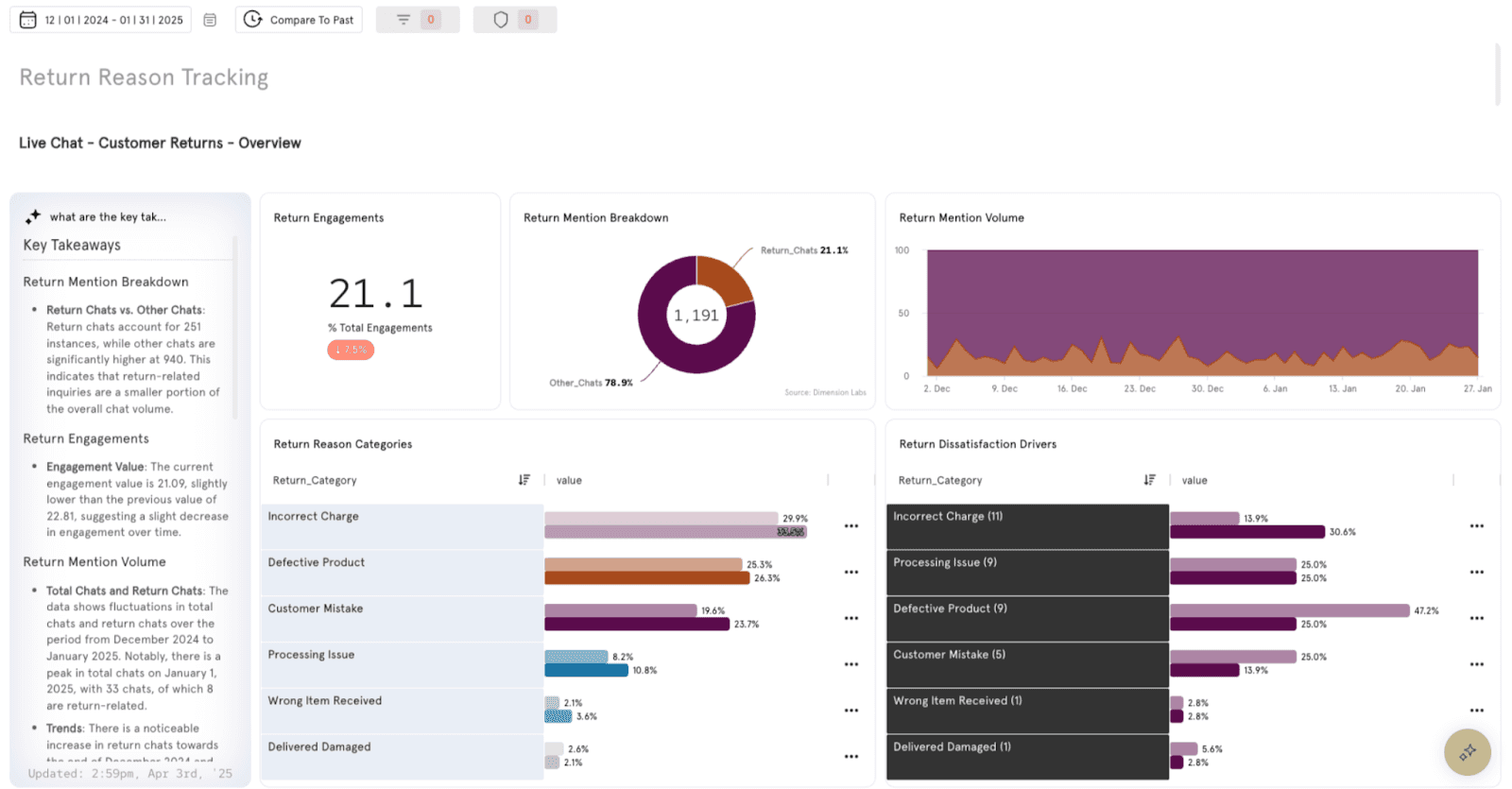
Business impact:
Product teams fix actual defects, not symptoms.
Ops teams avoid wasting resources on the wrong fixes.
Executives allocate budget to the real drivers.
Customer Story: An e-commerce retailer assumed logistics delays were killing customer experience. Analysis showed 40% of “shipping” complaints were actually about inaccurate delivery estimates in the app. Fixing the UI eliminated most complaints without touching the supply chain.
#7 — Predictive Profiling
Structured data tells you who customers are (age, income, geography). Unstructured data tells you how they think, feel, and behave.
By clustering language across interactions, companies can build segments around needs, attitudes, and intent. For example:
“Stressed budget-conscious” customers.
“Feature-seeking power users.”
“Loyal advocates who amplify brand sentiment.”
These segments go beyond marketing demographics. They reflect emotional and behavioral truth.

Business impact:
Marketing teams can target based on intent, not just demographics.
Product teams can design features for hidden personas.
Executives can reposition offerings around real needs.
Customer Story: The NBA leveraged unstructured data across multiple channels and created 6 predictive fan profiles to enable near-perfect attribution of feedback themes by fan type. These fan profiles help fuel more personalized engagement, reducing churn and improving the fan experience.
#8 — Regulatory and Compliance Insights
For regulated industries, unstructured data is a compliance minefield. Agents may skip disclosures, customers may reveal risk, or employees may misstate policies. These violations rarely show up in structured reports.
By scanning unstructured conversations, companies can flag risks in real time:
“Advisor didn’t mention FDIC coverage.”
“Rep promised refund outside policy.”
“Disclosure not read.”
Business impact:
Legal and compliance teams prevent fines.
Executives avoid reputational damage.
Ops teams maintain audit readiness.
Customer Story: A healthcare insurer mined transcripts and found dozens of disclosure lapses that would have triggered regulatory penalties. Fixing it saved millions in potential fines.
This is just the beginning. Unstructured data is the closest proxy we have to the “voice of truth.” And most organizations are sitting on it unused.
Why This Matters Now
Two forces are colliding:
1) Explosion of unstructured data. By 2025, more than 80% of enterprise data will be unstructured.
2) Advances in AI/LLMs. It’s now possible to enrich, cluster, and structure unstructured language at scale.
Yet most organizations still reduce this goldmine of data to sentiment + categories — the analytics equivalent of using a supercomputer to count word frequency.
The companies that break free of this mindset will:
Catch churn earlier.
See issues before they blow up.
Unlock new revenue from hidden signals.
Build more empathetic, customer-driven organizations.
This shift isn’t academic. It transforms outcomes for every function in the enterprise:
Data Teams: Move from “service providers” running dashboards to strategic enablers who unlock an entirely new class of data.
CX Leaders: Stop relying on low-response surveys and ticket tags; get a real-time, 100% coverage view of customer experience.
Product Teams: Learn exactly which features drive friction or delight — from the raw words of customers, not anecdotal feedback.
Executives: See churn, risk, and revenue opportunities faster than competitors.

The Path Forward: Operationalizing Language Data in the Modern Data Stack
Over the last two essays we laid the groundwork:
The Missing Layer in the Modern Data Stack: why today’s stack is brilliant for rows-and-columns but blind to conversational data, and why enterprises need an Unstructured Data ETL layer to make language a first-class citizen.
The Rise of the Language Data Engineer: the role (or responsibility set) that owns that layer—bringing software-engineering rigor to unstructured data so it’s trustworthy, governed, and reusable.
This piece is the bridge between those two ideas: how to put the layer and the role into motion.
The Operating Budget
To make language data durable and useful across your organization, stand up a repeatable pipeline that:
Ingests conversations from calls, chats, emails, reviews, and surveys (streaming or batch), with lineage and PII controls.
Normalizes sessions, speakers, timestamps, and metadata into a consistent conversational schema.
Enriches with predictive dimensions—churn risk, effort, CSAT, intent, root cause, upsell signals, compliance flags—using auditable, versioned models.
Outputs clean, BI-ready tables and views that plug directly into Snowflake/Databricks, dbt models, and your BI tools (Looker, Tableau, Power BI, Hex).
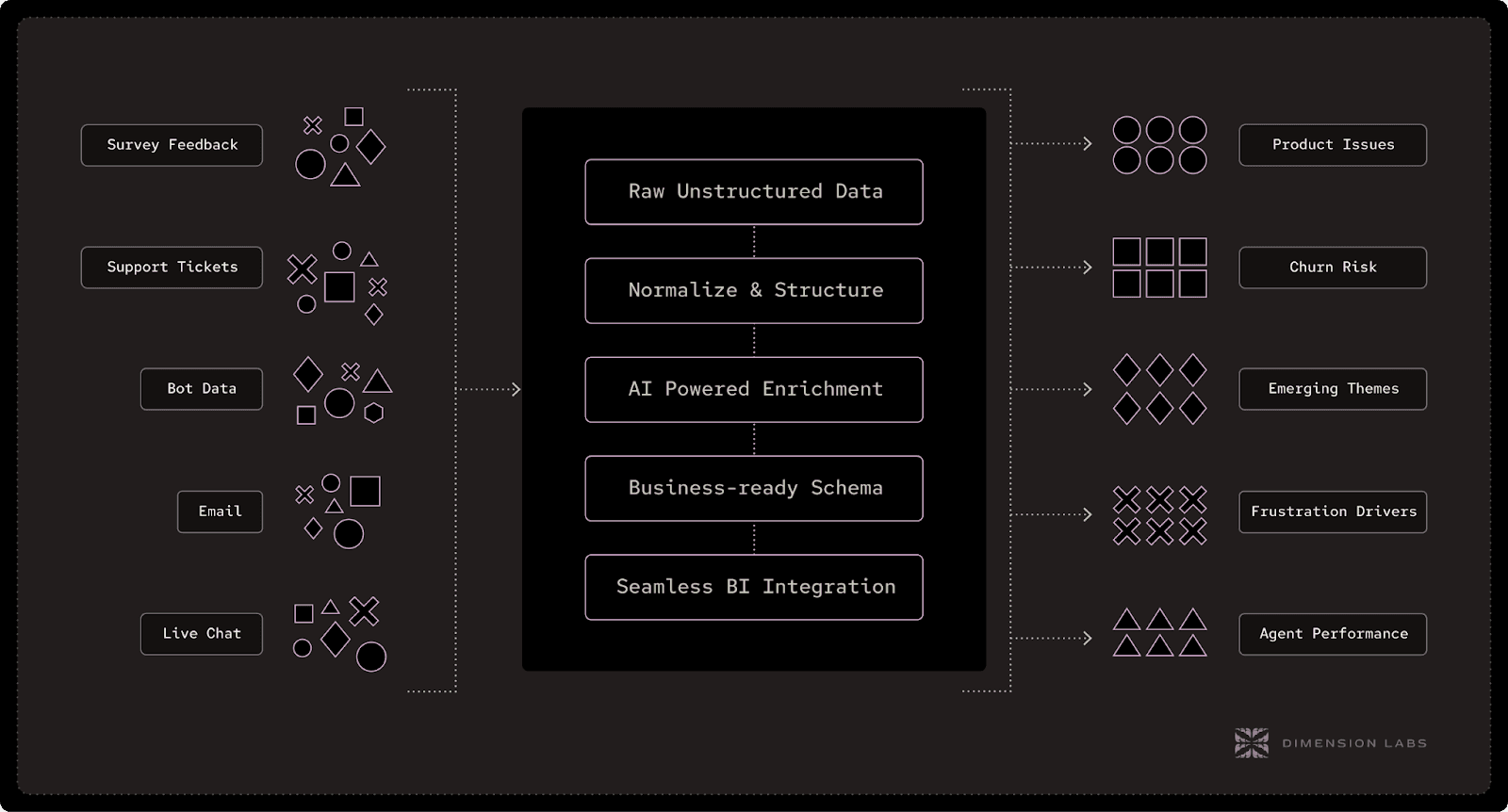
This is the Unstructured Data ETL layer we described in The Missing Layer. And the owner of this pipeline—the person who treats conversations like data products, manages schemas and prompts like code, and ships SLA-backed outputs—is the Language Data Engineer we introduced in Rise of the LDE.
When this layer and role are in place, enterprises move from “sentiment + categories” to actionable, always-on intelligence: early churn detection, predicted CSAT/Effort, emerging-issue alerts, upsell triggers, agent coaching signals, and compliance monitoring—all joined to your existing warehouse entities (accounts, orders, products) for real impact.
Just as dbt became the missing layer for structured transformation, Dimension Labs provides the missing layer for language—and a clear path for your data team to operationalize it with the LDE discipline.
Closing Thought
The biggest blind spot in business isn’t a lack of dashboards. It’s that we’ve ignored the 80% of data that actually tells us why customers feel, act, and decide the way they do.
Sentiment and categories were the first chapter of text analytics. But the next chapter is here: churn risk, predicted satisfaction, emerging issues, upsell signals, compliance risks, and more — all hidden in the words your customers are already giving you.
The companies that embrace this shift won’t just have better dashboards. They’ll have a better map of reality. And in business, that’s everything.