
The Rise of the Language Data Engineer
The Modern Data Stack’s Blind Spot
Over the last decade, the modern data stack has gone from niche idea to mainstream. Tools like Snowflake, dbt, and Looker redefined how companies ingest, transform, and activate data. Entire roles were born out of this movement — most famously, the Analytics Engineer, a position that didn’t exist ten years ago but is now indispensable.
But here’s the reality: the modern data stack was built for structured data. Numbers, rows, columns, events. And while that data is essential, it only tells half the story.
The other half? The unstructured language data that every business already collects but doesn’t know how to use: customer calls, support chats, survey responses, agent notes, online reviews, community posts. In 2025, more than 80% of enterprise data is unstructured. It’s the richest signal companies have — and the least leveraged.
This blind spot is no longer sustainable. We explored this blind spot in depth in our blog post on The Missing Layer in the Modern Data Stack: Unstructured Data, which outlines why unstructured conversations are the richest yet least leveraged data enterprises own.
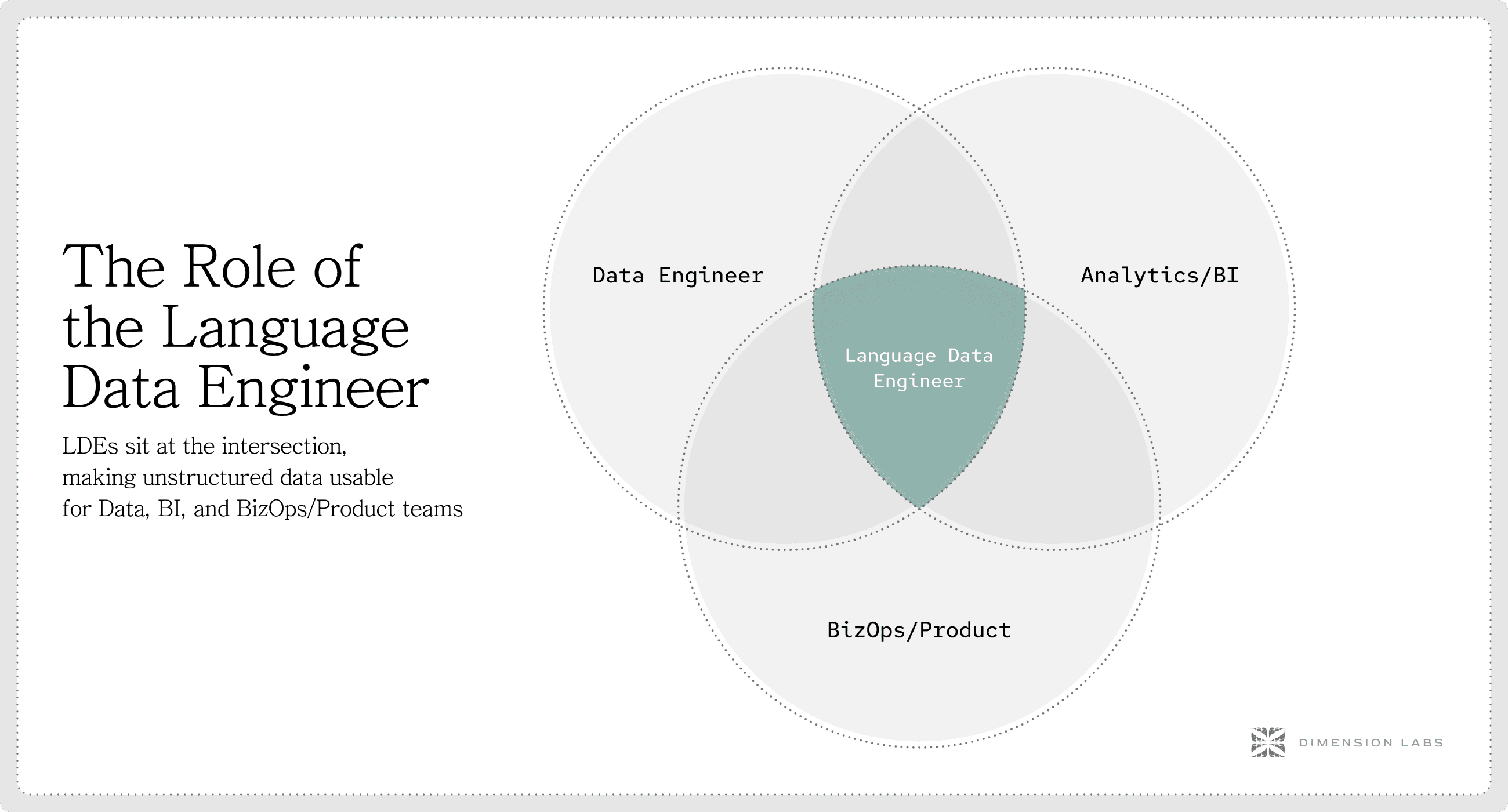
Just as analytics engineers emerged to operationalize structured data transformations, we now need a new role: the Language Data Engineer (LDE).
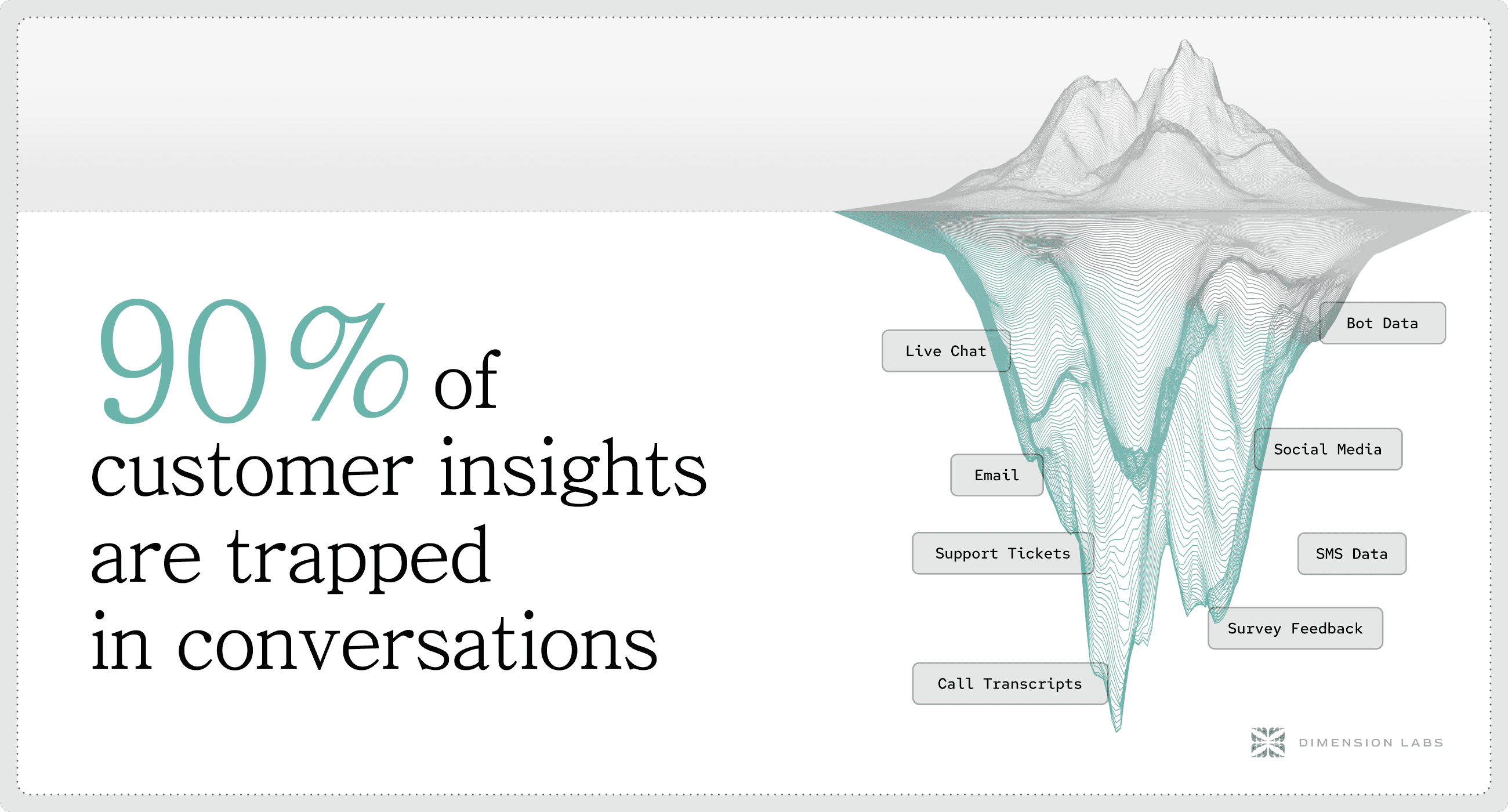
Why Language Data?
Language is the closest thing we have to the customer’s raw truth.
When a customer says, “The app keeps freezing when I try to upload photos,” that’s more actionable than any NPS score. When hundreds of support chats cite “billing confusion,” that’s the early warning sign of churn. When product testers write in feature requests, those are roadmap gold.
But here’s the problem: none of this makes it into the warehouse.
Today, most companies treat unstructured data as a side project:
Manually tagging support tickets.
Copy-pasting survey comments into spreadsheets.
Running brittle Python notebooks to hack together analysis.
Buying point tools that lock insights in siloed dashboards.
Unlike structured data (tables, rows, schemas), language data is inherently freeform. It comes as utterances, fragments, and conversations without a predefined schema. Every sentence can contain multiple intents, emotions, or signals. That richness makes it powerful—but also far more complex to normalize, enrich, and integrate into traditional BI workflows.
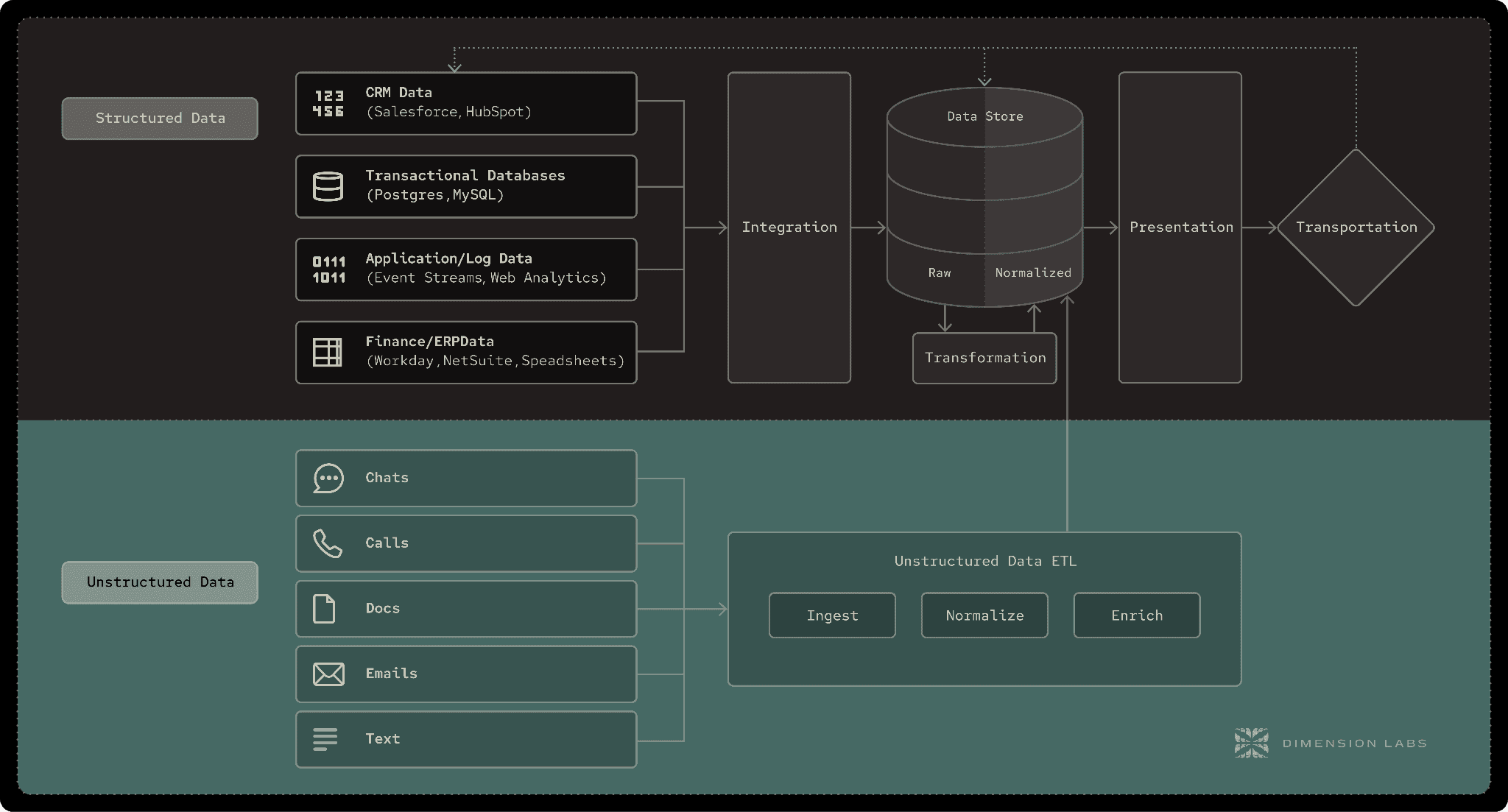
The result? Customer-facing teams get fragments. Data teams ignore the problem. And executives make strategic decisions blind to the voice of the customer.
This gap underscores the need for a new role: the Language Data Engineer (LDE)—a data professional trained to work with unstructured sources, operationalize them into the warehouse, and ensure organizations can finally make decisions powered by the full spectrum of customer truth.
The Language Data Engineer Defined
A Language Data Engineer (LDE) is the missing link between raw conversations and business intelligence. They are responsible for making language data a first-class citizen in the modern data stack.
Concretely, that means:
Ingestion — Pulling data from calls, chats, surveys, reviews, and other conversational sources.
Normalization — Splitting messy logs into clean sessions, removing noise, anonymizing PII.
Enrichment — Using AI to label sentiment, topics, intent, root cause, effort, churn risk.
Schema Mapping — Organizing enriched data into structured tables that align with business models.
Activation — Delivering BI-ready datasets into Snowflake, BigQuery, Tableau, Power BI, or Hex — so language data can be joined with structured data and analyzed by everyone.
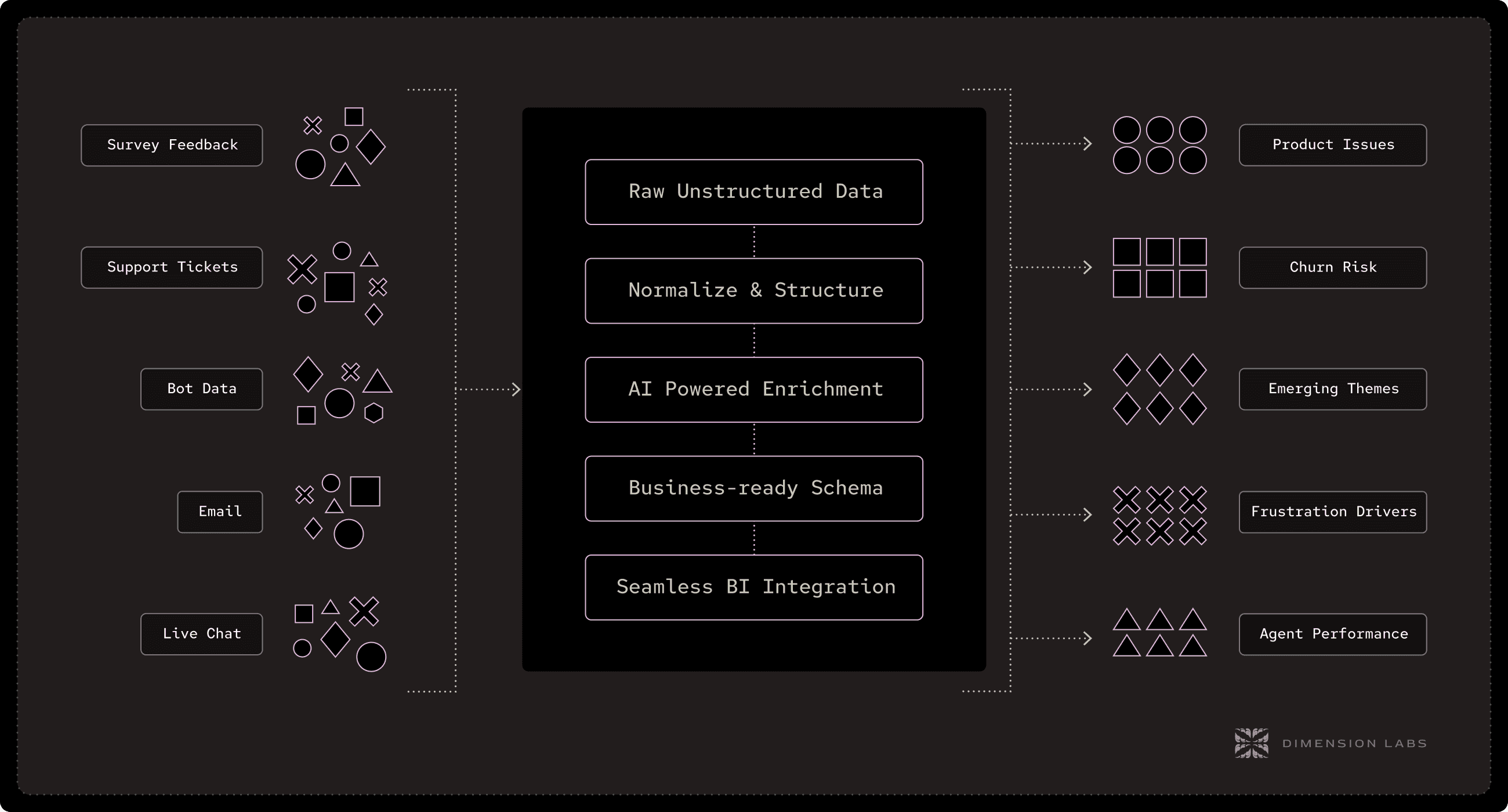
Where the analytics engineer bridges data engineers and analysts, the LDE bridges unstructured language and structured analysis. Unlike data or analytics engineers, the language data engineer’s toolkit extends into natural language processing, enrichment pipelines, and semantic transformations — skill sets designed specifically to handle unstructured, text-heavy sources.
Skills of a Language Data Engineer:
Natural Language Processing (NLP) fundamentals
Data enrichment and labeling with AI/LLMs
Text and log transformation/cleaning
Schema design for unstructured-to-structured mapping
Familiarity with BI/analytics workflows and warehouses
The rise of the Language Data Engineer is just the beginning. We see this as the first specialization in a broader discipline we call Semantic Engineering — the practice of turning all forms of unstructured data into structured meaning. Language is where this starts, because it is the richest and most business-critical signal for enterprises today. Over time, the same principles will extend to other unstructured sources like video, audio, and multimodal customer interactions.
Why This Role Matters Now
There are three reasons why the Language Data Engineer is no longer optional:
The Maturity of the Modern Data Stack
Structured data is solved. Companies have robust pipelines, mature modeling, reliable warehouses. The natural next frontier is bringing unstructured data into the same workflows.
The Rise of Large Language Models (LLMs)
For the first time, it’s technically feasible and affordable to enrich text at scale. What used to require armies of manual taggers or brittle NLP now takes minutes with orchestrated LLM pipelines.
Economic and Competitive Pressure
In a world where every company is expected to do more with less, ignoring the richest customer dataset you already own is no longer defensible. Companies that operationalize unstructured data will iterate faster, serve customers better, and outcompete peers.
The Impact of Language Data Engineers
Organizations that empower LDEs unlock massive advantages:
For BizOps leaders:
Real-time insight into why churn happens, why growth stalls, and what customers actually want.
For CX teams:
A consolidated view of customer pain points across every channel — without manual tagging.
For Product managers:
A direct pipeline of feature requests, UX issues, and friction points tied to customer segments.
For Executives:
The ability to tie financial and usage metrics directly to customer language — connecting “what happened” to “why it happened.”
For AI initiatives:
Clean, labeled language data that supercharges predictive models and generative AI agents.
In short: LDEs turn raw conversations into competitive advantage.
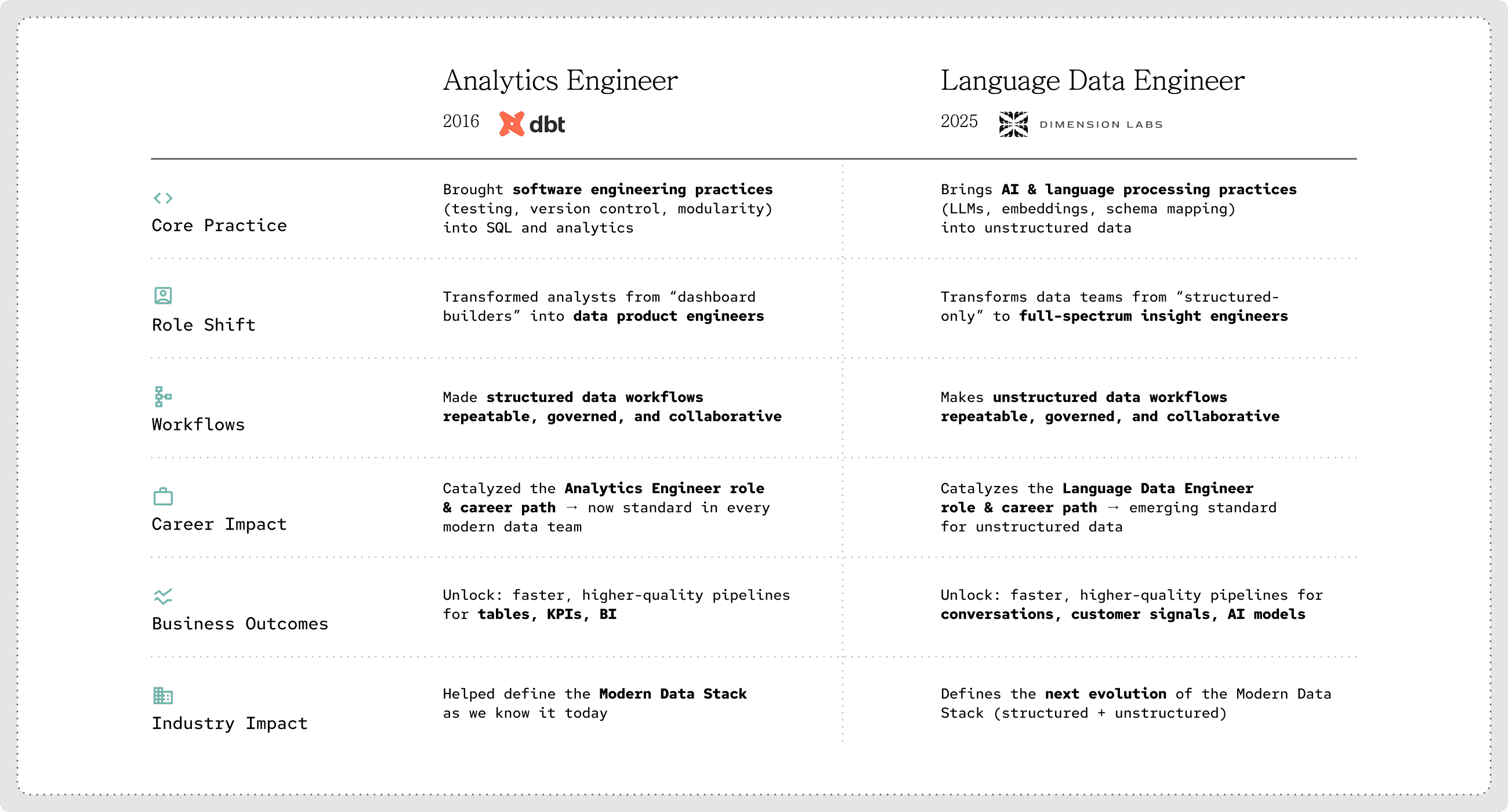
A Historical Parallel: The Analytics Engineer
When dbt introduced the concept of the analytics engineer, the data world changed.
Before then, analysts were stuck writing SQL in silos while data engineers owned ETL pipelines. There was no clear role for someone who could apply software engineering practices (testing, version control, modularity) directly to analytics. By naming this role, dbt crystallized a movement. The Analytics Engineer unlocked an entire category, a community, and a new way of working with structured data.
The Language Data Engineer represents the same kind of shift — but for unstructured data.
Just as the Analytics Engineer formalized the bridge between raw data pipelines and business intelligence, the Language Data Engineer fills the missing link for unstructured conversations. Importantly, this doesn’t always mean companies must create an entirely new role.
Some teams may evolve existing Data Engineers or Analytics Engineers to take on LDE responsibilities. Others may formalize it as a distinct specialization. Either way, the skillset is becoming essential to making unstructured conversations a first-class citizen in the Modern Data Stack.
What This Means for Data Leaders
If you’re a CDO, Head of Analytics, or BizOps leader, you should ask yourself:
Who owns unstructured data in my company today?
How are we integrating calls, chats, and surveys into our warehouse?
Do we have a repeatable pipeline for language data, or are we still hacking together scripts and tags?
Who is accountable for making this data usable across Product, CX, and Strategy?
If you don’t have answers, you’re already behind.
By 2027, hiring a Language Data Engineer will be as common as hiring an Analytics Engineer. The only question is whether your team will be ahead of the curve — or scrambling to catch up.
A Call to Action
The modern data stack isn’t complete without a language layer. And that layer won’t operationalize itself.
Every company will need a Language Data Engineer — the person who ensures unstructured data flows from raw conversations into BI-ready tables, powering dashboards, AI models, and decisions.
At Dimension Labs, we’re building the infrastructure that makes this role possible. Just as dbt became the backbone of the analytics engineer, our mission is to be the backbone of the Language Data Engineer.
This is more than a product story. It’s a paradigm shift.
And like every paradigm shift in data, it starts with a new role.
The rise of the Language Data Engineer is inevitable.
The only question is: will you be one of the first to embrace it?