
The Missing Layer in the Modern Data Stack: Unstructured Data
By 2025, more than 80% of enterprise data will be unstructured. Yet if you look at the modern data stack it’s almost entirely designed for structured data.
That means the most common, richest sources of customer truth (chat transcripts, call recordings, email threads, open-ended survey responses) remain invisible in most data-driven decision-making.
We’ve built an incredibly powerful stack… but it’s missing a critical layer. This post explores why that gap exists, what the “missing layer” should look like, and how adding it can transform how your organization uses data to make decisions.
What the Modern Data Stack Gets Right—and What It Misses
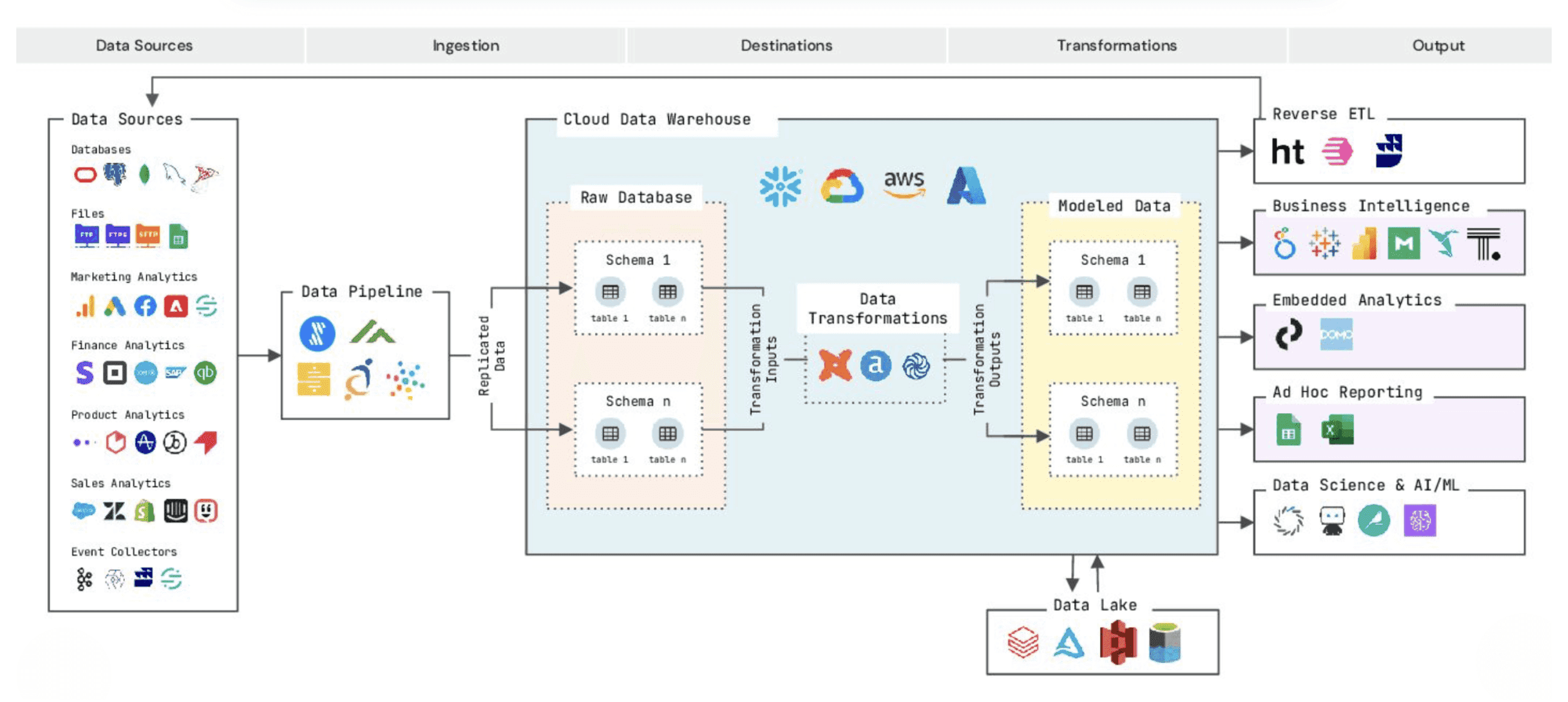
Over the past decade, the Modern Data Stack (MDS) has gone from an emerging concept to the default architecture for analytics at many organizations. It began with the rise of cloud data warehouses like Amazon Redshift and Google BigQuery in the early 2010s, which made large-scale analytics affordable and eliminated the need for on-premises infrastructure. Soon after, automated ingestion tools like Fivetran and Stitch shifted the industry from traditional ETL to ELT, enabling raw data to be loaded directly into the warehouse and transformed later. This set the stage for the next leap forward: the transformation layer. Tools like dbt standardized how data teams modeled, cleaned, and tested warehouse data, making transformation a first-class part of analytics workflows.
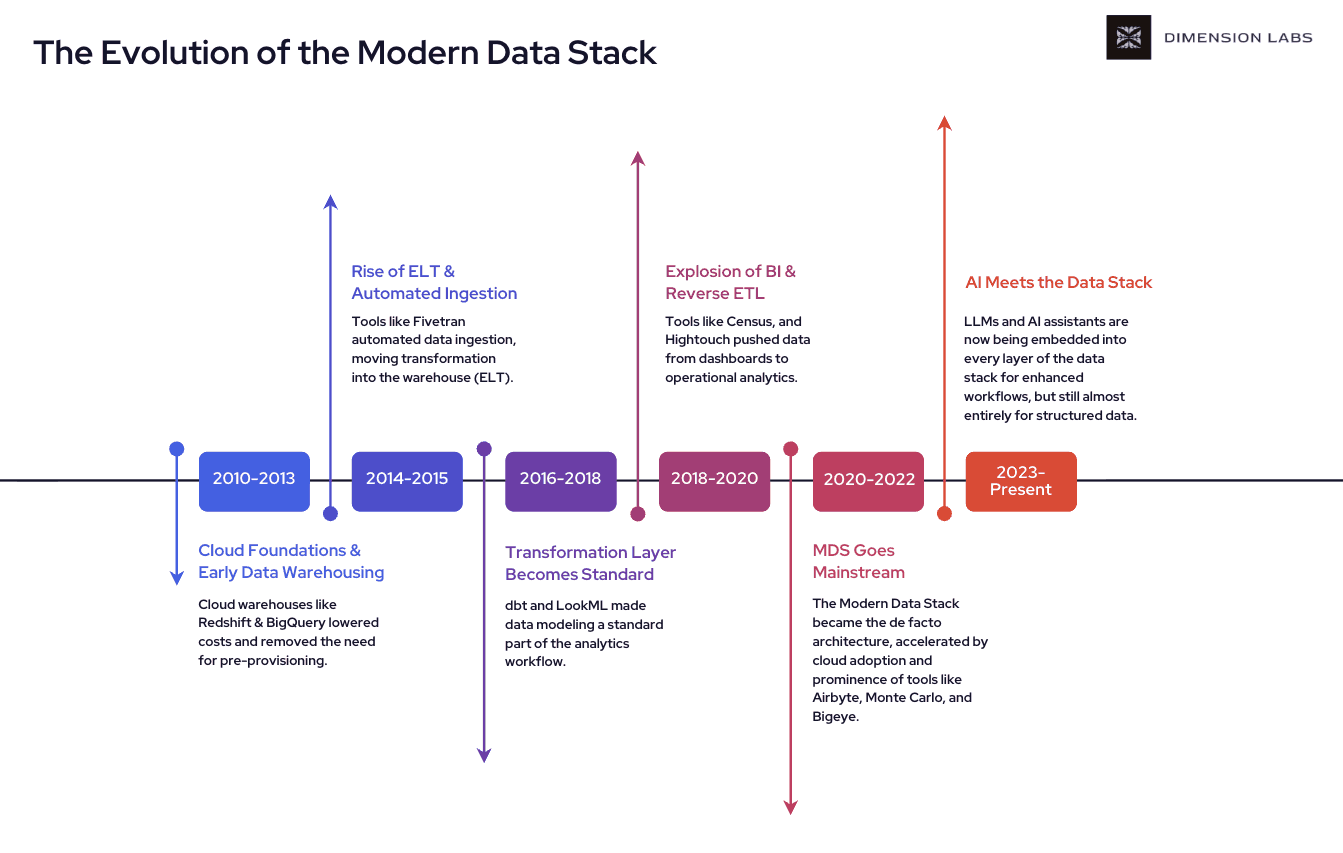
By the late 2010s, the stack matured with powerful business intelligence tools like Looker, Tableau, and Hex, along with reverse ETL platforms such as Census and Hightouch that pushed insights back into operational systems. The result was a streamlined data pipeline: ingestion, storage, transformation, and visualization — all optimized for structured data. Data observability platforms like Monte Carlo and Bigeye emerged to keep this structured data reliable, while the adoption of AI in recent years has started to make querying and insight generation even faster.
This architecture works beautifully for structured data — anything that fits neatly into tables, with rows and columns.
🛑 The problem: the MDS doesn’t natively handle unstructured data — especially the vast, messy, language-rich datasets that tell you why customers behave the way they do. By 2025, more than 80% of enterprise data will be unstructured — things like chat transcripts, call center notes, open-ended survey responses, and online reviews. These are some of the richest sources of customer truth, but they don’t fit neatly into rows and columns. As a result, they remain siloed in platforms like Zendesk, Qualtrics, and contact center software, invisible to the warehouse and BI tools that drive most business decisions.
The next evolution of the MDS will be the Unstructured Data ETL layer — a standardized way to ingest, clean, enrich, and structure language data so it becomes a first-class citizen in the analytics ecosystem.
The Consequences of Ignoring Unstructured Data
Every business is sitting on a massive and constantly growing pile of unstructured customer data. This is the data your customers produce naturally in the course of interacting with you — not in carefully designed surveys, but in their own words, in real-world contexts.
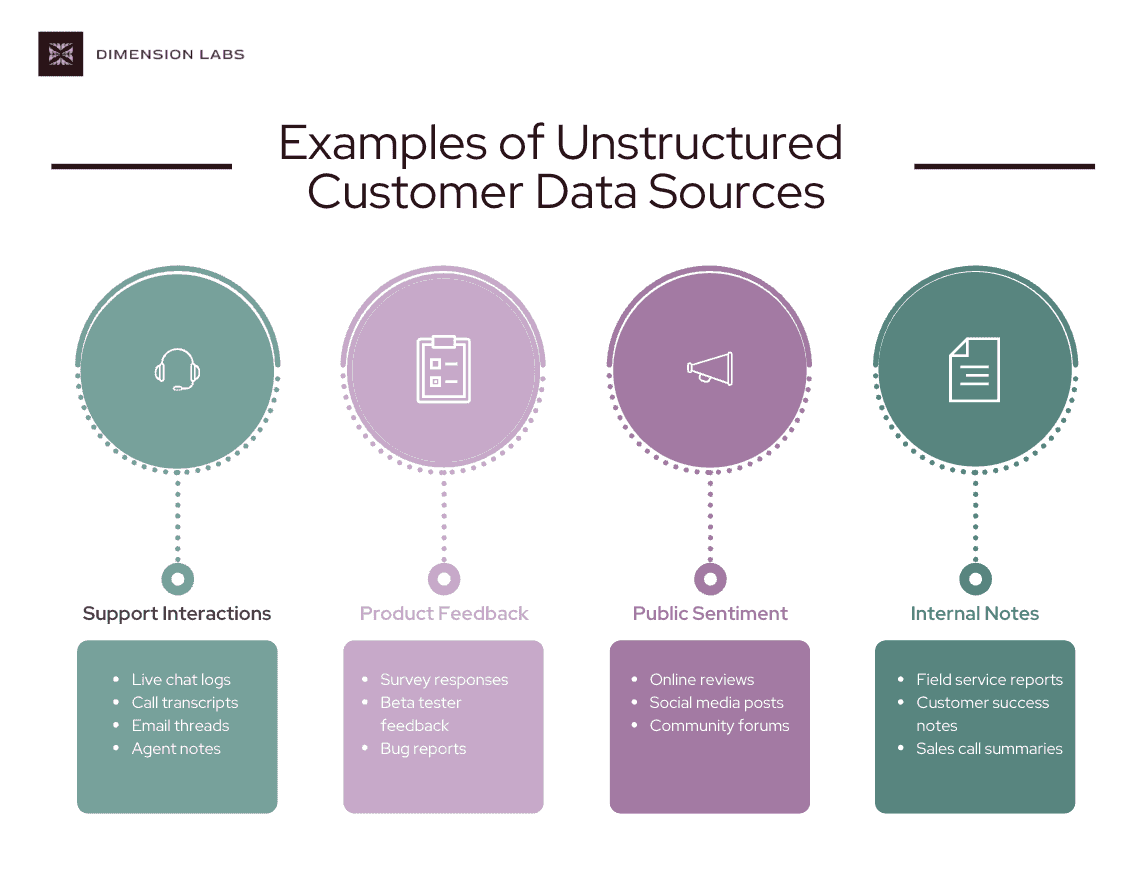
Examples of unstructured data can include:
Support Interactions:
Live chat logs from your website or mobile app.
Call transcripts from your contact center (transformed with voice-to-text).
Email threads between customers and support agents.
Agent notes written during or after customer calls.
Product Feedback:
Open-ended survey responses (NPS, CSAT, post-purchase feedback).
Beta tester feedback during early feature releases.
Bug reports from support portals or in-app feedback forms.
Public Sentiment & Brand Conversations:
Online reviews (Google, Yelp, Trustpilot).
Social media posts & comments (Twitter/X, Facebook, LinkedIn, Reddit).
Community forums or user groups.
Internal Operational Notes:
Field service reports from technicians in the field.
Customer success notes from QBRs or account reviews.
Sales call summaries from CRM platforms.
Most of this is already collected somewhere — in Zendesk, Intercom, Salesforce, Qualtrics, Genesys, Gong, or other point solutions — but it is rarely:
❌ Centralized in the data warehouse.
❌ Normalized into a consistent structure.
❌ Standardized to a shared schema or taxonomy.
❌ Joined with other data sources.
❌ Made queryable by BI or analytics tools.
The result? Companies are sitting on a goldmine of “dark data” — information they already own but can’t see, search, or analyze systematically. And the consequences of ignoring it are serious:
1. Customer Experience Blind Spots
You’re basing CX strategy on the 5–10% of customers who fill out structured surveys, while ignoring the majority.
Silent churners — customers who leave without warning — often express frustration in support interactions long before they go. Without analyzing those conversations, you miss out on early warning signals.
2. Slower Product Iteration
Your product roadmap depends on anecdotal feedback from a few vocal customers or internal advocates.
Rich feature requests and bug descriptions in open-text feedback never reach product teams in a usable form.
3. Operational Inefficiency
Support teams manually tag tickets, leading to inconsistent categorization and wasted time.
The same root cause might be investigated multiple times because insights aren’t centralized or searchable.
4. Incomplete Business Intelligence
Dashboards track “what” is happening (churn rate, NPS, ticket volume) but not “why” it’s happening.
You can’t tie behavioral metrics to the actual language customers use, making it impossible to quantify the impact of recurring issues.
5. Missed Revenue Opportunities
Upsell and cross-sell signals hidden in conversations (e.g., “I wish you offered X…”) go unnoticed.
High-value accounts with growing dissatisfaction aren’t flagged early enough for intervention.
6. Weaker AI Performance
Without structured historical conversation data, AI models for customer support, churn prediction, or personalization have a weaker foundation and produce lower-quality outputs.
Gen AI experiences such as chatbots also introduce brand risk, if you are unable to analyze the quality of output in the conversations.
Ignoring unstructured data is like running your business with 80% of your vision blocked. You may still move forward, but you’ll miss opportunities, overlook risks, and make decisions without the full context.
Why the Gap Exists
If unstructured data is so valuable, why isn’t it already part of the Modern Data Stack? The answer is simple: the MDS was never designed for it.
The Modern Data Stack — as it exists today — is built on a foundation of structured, schema-defined data. That’s why it works so well for transactional data from ERP systems, clickstream data from analytics platforms, and operational data from SaaS apps. These sources already fit neatly into rows and columns. Unstructured data does not.
Here’s why the gap exists:
No Native Schema
A chat log doesn’t have a consistent table structure.
Conversations can vary in length, topic, and language.
Even if you drop raw JSON or text blobs into a warehouse, you can’t query them meaningfully without first structuring them.
Complex Cleaning Requirements
Unstructured sources require advanced preprocessing:
Splitting long logs into individual conversational sessions.
Merging partial records from different systems.
Removing or anonymizing PII to maintain compliance (GDPR, CCPA).
Specialized Enrichment Needs
You need Natural Language Processing (NLP), Large Language Models (LLMs), and vector embeddings to extract sentiment, topics, intent, and root cause.
These capabilities aren’t built into the core MDS tools — they require specialized infrastructure.
Fragmented Tooling
The typical enterprise uses multiple tools for support, surveys, and social media monitoring.
Each tool has its own API, export format, and limitations.
Stitching these together is costly and brittle.
High Engineering Lift for In-House Solutions
Data teams often try to build custom unstructured pipelines themselves.
These are expensive to maintain, hard to scale, and require rare skill sets that blend data engineering, NLP, and domain knowledge.
BI Tool Limitations
Looker, Tableau, and other BI platforms are designed for querying structured data.
Even if you ingest raw unstructured data, BI tools can’t visualize or aggregate it without heavy preprocessing.
⚠️ The net effect: unstructured data remains trapped in the operational systems where it’s created, inaccessible to the very tools and workflows that drive the rest of the business forward.
This is exactly why the next evolution of the Modern Data Stack will require a dedicated Unstructured Data ETL layer — purpose-built to bridge this gap.
The Missing Layer: Unstructured Data ETL
We believe the Modern Data Stack needs a new standard layer — one that does for conversational and free-text data what dbt did for structured tables.
We call this Unstructured Data ETL.
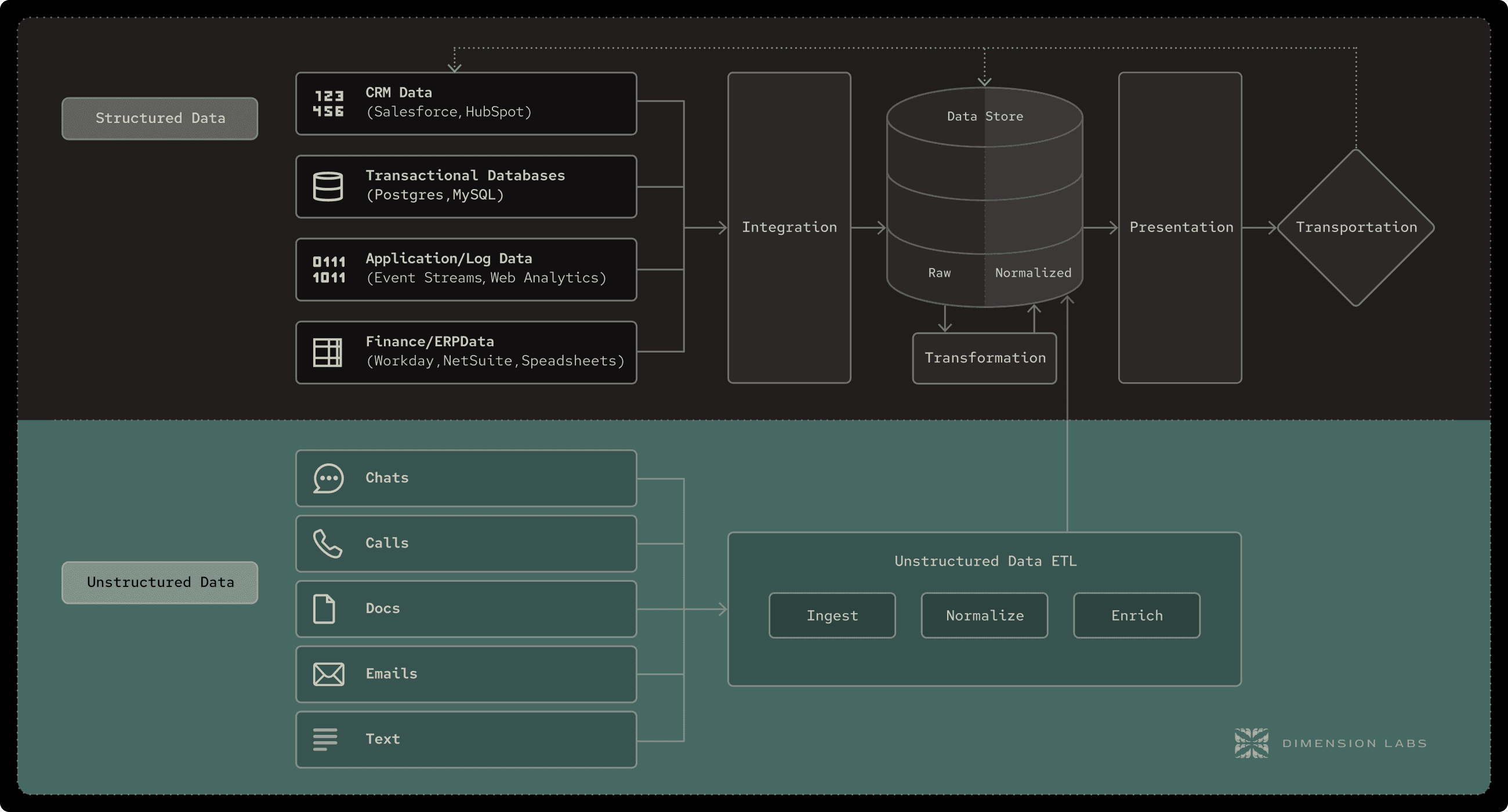
This isn’t a “nice-to-have” — it’s the only way to consistently unlock the 80% of enterprise data that’s currently invisible to decision-making. Right now, companies either ignore unstructured data entirely or hack together ad hoc pipelines that are brittle, expensive to maintain, and impossible to scale.
The job of the Unstructured Data ETL layer is to:
Ingest from any unstructured source — APIs, batch exports, direct database pulls, or streaming sources like Kafka. The goal is source-agnostic flexibility, so you can unify call center transcripts from Genesys, NPS comments from Qualtrics, and sales call summaries from Gong into one pipeline.
Normalize and clean raw inputs — Split multi-interaction logs into sessions, merge partial records, remove or mask PII, and standardize metadata like timestamps and customer IDs. This transforms raw text chaos into consistent, analytics-ready records.
Enrich with AI-driven dimensions — Use LLM orchestration and embeddings to classify sentiment, detect topics, surface root causes, and score effort. Crucially, this can be tailored to your domain — the “effort” score for a banking call is different from one for a hotel booking.
Map to a reusable schema — Instead of dumping unstructured text directly into your warehouse, you output structured tables with defined columns: Category, Sentiment, Root Cause, Product Area, Resolution Time, etc. This is what makes language data queryable with SQL, visualizable in BI tools, and joinable to other datasets.
Push BI-ready outputs back into the warehouse — Just like structured ETL, the final step is delivering the transformed dataset where your data teams already work — Snowflake, BigQuery, Redshift — so it plugs directly into the rest of your analytics ecosystem.
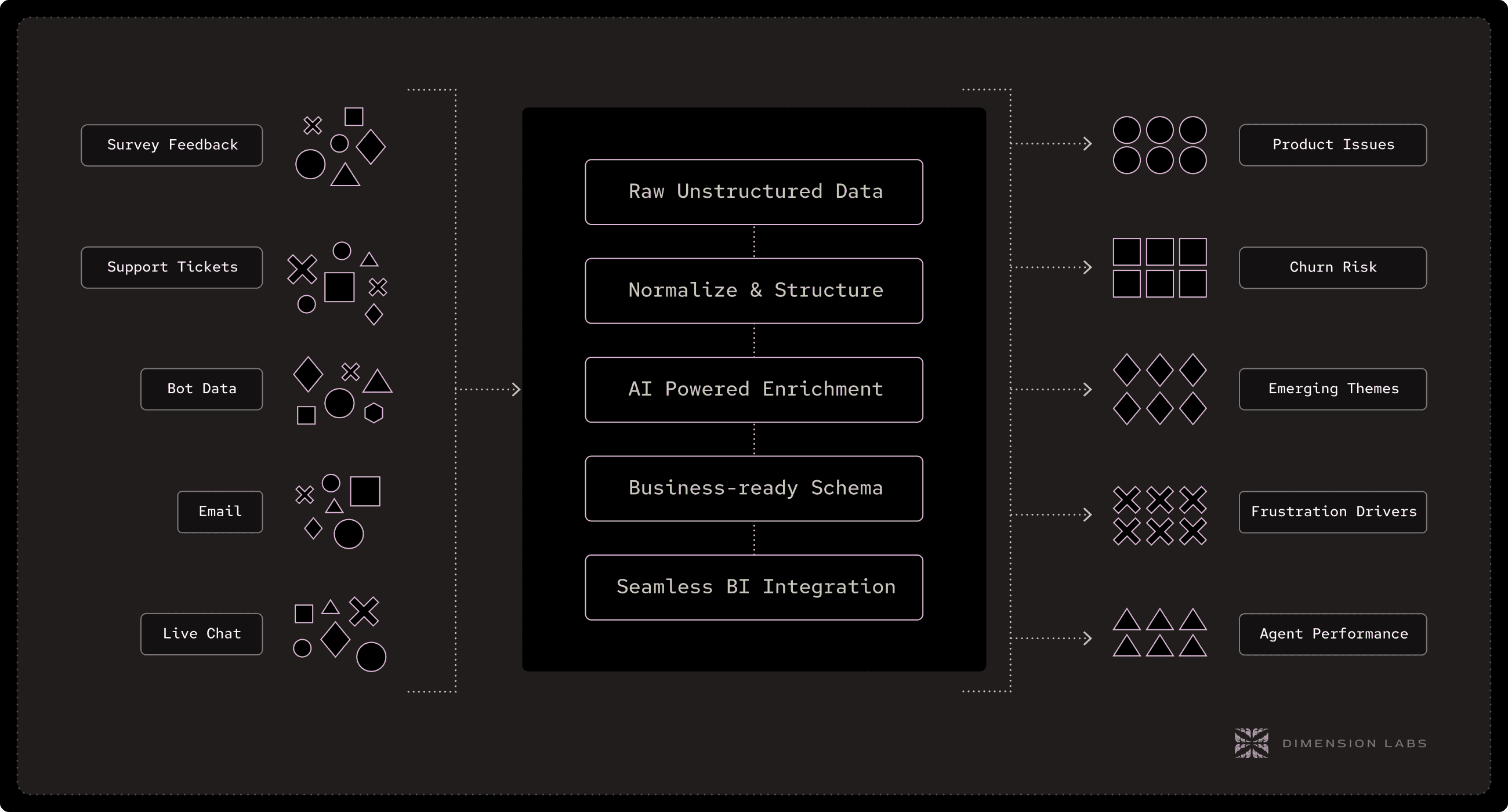
Why this layer is essential:
Without it, unstructured data remains siloed in operational tools, unusable for analytics. With it, you transform “dark data” into first-class citizens in the MDS — available to the same dashboards, ML models, and decision processes as structured data.
How This Fits into the Modern Data Stack
The Unstructured Data ETL layer isn’t meant to replace any part of the MDS — it’s meant to slot in alongside the existing layers, enhancing data quality and completeness.
Here’s how it fits:
Ingestion: Works in parallel to tools like Fivetran, Airbyte, or custom pipelines — but instead of pulling in rows from SaaS APIs into a table, it’s ingesting conversation logs, reviews, and other text data.
Transformation: Just as dbt models transactional data into analytics-ready tables, Unstructured Data ETL models conversational data into structured, dimensional datasets.
Storage: Output lands in your central warehouse, just like any other fact or dimension table, ready to be joined with other sources.
Visualization & Activation: Once it’s in the warehouse, Looker, Tableau, Hex, or reverse-ETL tools can consume it — surfacing language insights alongside your KPIs, or pushing them back into CRMs, support platforms, or marketing automation tools for activation.
A complete MDS pipeline for unstructured data might look like this:
Ingestion: Pull chat, call, survey, and review data from source systems (via API or batch).
Normalization: Split into sessions, standardize metadata, remove PII.
Enrichment: Run through multi-model LLM orchestration to generate sentiment, topics, intent, root cause, and other domain-specific labels.
Schema Mapping: Map to a defined analytics schema (e.g., Category, Sentiment, Effort Score, Product Area).
Warehouse Output: Write BI-ready tables back into Snowflake/BigQuery.
Visualization & Activation: Use in BI dashboards, AI models, or push to operational systems for real-time action.
The key shift:
Unstructured data stops being an afterthought handled in separate “voice of the customer” tools — it becomes a native, queryable, joinable dataset in your MDS, powering cross-functional insights.
Example: Instead of “Our NPS dropped by 5 points last quarter” (what), your dashboard now shows: “Our NPS dropped by 5 points last quarter, primarily due to check-in delays at three specific locations, as flagged in 18% of guest chats” (why).
Business Impact: Why It Matters Now
Implementing an Unstructured Data ETL layer doesn’t just improve analytics — it changes how the entire organization operates. Different stakeholders across the business feel this impact in unique, tangible ways:

For Data & Analytics Engineers
Eliminate ad hoc pipelines: No more one-off scripts for every source of unstructured data — one standardized, reusable pipeline handles all ingestion, cleaning, and enrichment.
Increase data reliability: Clean, schema-mapped conversational data in the warehouse reduces data debt and ensures reproducibility.
Faster project delivery: Prebuilt enrichment and mapping functions mean analytics engineers can deliver new datasets to stakeholders in days, not months.
For Data Leaders (CDOs, Heads of Analytics)
Full customer visibility: Finally integrate unstructured data into the MDS to achieve a 360° view of the customer — the “why” alongside the “what.”
Better ROI on warehouse investments: The data warehouse becomes the single source of truth for all customer data, not just transactional or survey data.
Scalable governance: Standardized ingestion, PII handling, and schema mapping reduce compliance risk while improving auditability.
For CX and Support Leaders
Prioritize what matters most: See the actual top drivers of customer dissatisfaction in real time, not just anecdotal escalations.
Faster root cause resolution: Identify systemic issues (e.g., 23% of call transcripts in Q3 cite payment errors) and work cross-functionally to resolve them.
Cost savings: Reduce manual ticket tagging, repetitive customer investigations, and handle times.
For Product Leaders
Faster feedback loops: Turn open-ended feedback into structured insights that can be acted on during sprint planning — improving feature adoption and reducing churn.
Risk detection: Spot emerging product issues before they escalate into PR crises or revenue loss.
Competitive advantage: Use real customer language trends to inform market positioning and product roadmaps.
For Executives & Strategy Leaders
Decision-making with full context: Move beyond KPI dashboards to truly understand why metrics change.
Quantifiable ROI: Tie improvements in NPS, retention, or operational efficiency directly to actions taken from unstructured data insights.
Stronger AI strategy: Structured unstructured data powers more accurate downstream AI models — from churn prediction to personalization engines.
Why This Moment is Different
The idea of analyzing unstructured data isn’t new — companies have been trying for decades, often with keyword-based sentiment tools, social listening platforms, or expensive consulting projects. But until recently, the effort was costly, slow, and hard to scale.
Today, four major shifts make this the perfect moment for Unstructured Data ETL to become a standard MDS layer:
⚡ LLM Maturity & Affordability—Modern large language models can classify, summarize, and label text at scale with speed and accuracy that was impossible even two years ago — at a fraction of the cost of legacy NLP approaches.
⚡ Data Stack Readiness—Most enterprises already have a robust MDS in place for structured data — making it far easier to slot in an unstructured layer without overhauling infrastructure.
⚡ Economic & Competitive Pressures—Leaders are under pressure to find efficiency gains and revenue opportunities without expanding headcount. Unstructured data is a “goldmine” of already-collected insights that can drive measurable impact quickly.
⚡ Cultural Shift in Data Teams—Analytics engineering and the dbt movement have redefined what’s possible for data teams — making them more open to adopting new modeling layers when they see clear ROI.
The convergence of these factors means that what was once aspirational is now entirely practical — and those who move early will define the category.
The Path Forward
The “Unstructured Data ETL” layer is not a trend — it’s the inevitable next stage of the Modern Data Stack. Just as dbt became the standard for transforming structured data in warehouses, a similar standard will emerge for ingesting, cleaning, enriching, and modeling unstructured language data.
Our vision: Every data team should be able to treat unstructured data as easily as SQL tables — no brittle pipelines, no manual tagging, no siloed tools.
How to get started:
Audit your unstructured data sources — Identify where conversational and free-text data is stored today (e.g., Zendesk, Qualtrics, call center logs).
Pick a high-impact pilot use case — For example, combining support ticket data with product usage data to understand churn drivers.
Implement an Unstructured Data ETL pipeline — Focus on ingestion flexibility, schema mapping, and enrichment tailored to your domain.
Integrate into your MDS — Push the resulting datasets back into your warehouse and BI tools so they become part of standard analytics workflows.
Measure & expand — Track ROI through time savings, cost reduction, and revenue lift — then expand coverage to new sources and teams.
The winners in this next phase of the data stack will be those who act now. If you’re not operationalizing your unstructured data, you’re making decisions with one eye closed — and your competitors won’t be.