
A Guide to Unstructured Data Management
In today’s data-driven world, organizations are inundated with vast amounts of information, much of which is unstructured. Unlike traditional structured data neatly organized in databases, unstructured data includes emails, call transcripts, social media posts, live chats, and more. Managing this type of data effectively is becoming a critical business imperative. According to DemandTalk, in 2022, 90% of organizational data was unstructured, totaling an astonishing 57,280 exabytes. This explosive growth presents both challenges and opportunities for enterprises aiming to leverage their data fully.
This guide explores what unstructured data management entails, the common challenges organizations face, best practices to adopt, and how modern data architectures are evolving to address these needs.
What Is Unstructured Data Management?
Definition and Core Concepts
Unstructured data management refers to the processes, technologies, and strategies used to collect, store, organize, analyze, and derive insights from data that does not conform to traditional database schemas. This data type includes text documents, images, audio files, video content, social media interactions, and conversation data, among others. Unlike structured data, which fits into rows and columns, unstructured data is inherently more complex and diverse.
Effective management involves cataloging all sources, normalizing formats, ensuring data quality, and enabling advanced analytics such as natural language processing (NLP) and machine learning. As Edward Calvesbert, Vice President of Product Management at IBM watsonx, notes, “Most data being generated every day is unstructured and presents the biggest new opportunity”.
Organizations are increasingly recognizing the importance of unstructured data management as a critical component of their overall data strategy. With the rise of big data and the Internet of Things (IoT), the sheer volume of unstructured data generated daily is staggering. For instance, social media platforms alone produce billions of posts, comments, and images every hour, all of which can provide valuable insights into consumer behavior and preferences. By harnessing this data, businesses can enhance their decision-making processes, improve customer engagement, and drive innovation in their products and services.
How It Differs From Structured Data Management
Structured data management typically revolves around relational databases and data warehouses where data is organized into predefined schemas. This allows for straightforward querying and reporting. In contrast, unstructured data lacks a fixed format, making it harder to index, search, and analyze using traditional tools.
Unstructured data often requires specialized tools that can clean & normalize the data, enrich or tag the data with LLMs, and output the data in analytics-ready formats. The volume and variety of unstructured data also tend to be much larger, demanding scalable storage and processing solutions that can handle diverse formats and sources. For example, while structured data might be easily managed through SQL queries, unstructured data often necessitates the use of machine learning algorithms to identify patterns and extract meaningful information. This complexity not only poses challenges in data management but also opens up new avenues for innovation, as organizations leverage advanced technologies to unlock the potential hidden within their unstructured data assets.
Why Unstructured Data Management Matters in 2025
80% of Enterprise Data Is Still Invisible
Despite advances in data analytics, a significant portion of enterprise data remains unstructured and largely untapped. Recent reports indicate that approximately 85% of enterprise data is unstructured, complicating data governance and utilization efforts.
This “invisible” data often holds critical insights into customer behavior, operational efficiency, market trends, and key product feedback. Without proper management, organizations risk missing out on valuable intelligence that can drive competitive advantage. The challenge lies not only in recognizing the existence of this data but also in developing the tools and frameworks necessary to analyze and leverage it effectively. As businesses evolve, the ability to harness unstructured data will become a key differentiator in the marketplace, allowing organizations to make more informed decisions and respond swiftly to changing customer preferences.
The Cost of Ignoring Customer Conversations
Customer interactions through calls, chats, emails, and surveys generate massive amounts of unstructured data. Ignoring these conversations can lead to missed opportunities for improving customer experience, identifying pain points, and anticipating needs. For example, sentiment analysis on call center recordings or chat transcripts can reveal emerging issues before they escalate.
As organizations increasingly prioritize customer-centric strategies, integrating unstructured data from these channels into analytics workflows becomes essential to understand and respond effectively. The integration of machine learning algorithms can further enhance this process, providing predictive insights that allow businesses to tailor their offerings proactively. By analyzing historical customer interactions, companies can identify trends and preferences, enabling them to create personalized experiences that resonate with their audience and foster loyalty.
Opportunities Hidden in Calls, Chats, and Surveys
Unstructured data from voice calls, chatbots, and survey responses contains rich qualitative insights. Advanced AI techniques enable organizations to extract themes, detect sentiment, and even automate responses.
Recent industry collaborations highlight this trend. In June 2024, IBM partnered with Telefónica Tech to develop AI and analytics solutions enhancing multilingual content discovery and cognitive automation across regulated sectors, showcasing the growing focus on unlocking value from unstructured data.
Companies are beginning to recognize the potential of leveraging unstructured data not just for operational improvements but also for strategic decision-making. By employing natural language processing (NLP) techniques, organizations can analyze customer feedback at scale, uncovering insights that inform product development and marketing strategies.
Common Challenges of Managing Unstructured Data
Volume and Variety Across Sources
The sheer volume of unstructured data is staggering and comes from diverse sources—chats, calls, surveys, and social—that vary widely in format and quality. Managing such variety requires flexible architectures and scalable storage capable of handling heterogeneous data types. For instance, social media platforms generate vast amounts of text, images, and videos, each requiring different processing techniques. Moreover, the rapid growth of IoT devices adds another layer of complexity, as these devices continuously stream data that must be captured, analyzed, and stored in real-time. As a result, organizations must invest in advanced data management solutions that can adapt to the evolving landscape of unstructured data.
Tool Sprawl and Siloed Dashboards
Organizations often deploy multiple point solutions to manage different unstructured data types, leading to tool sprawl. This fragmentation results in siloed dashboards and inconsistent data governance, making it difficult to get a unified view or conduct comprehensive analysis.
Consolidating data and integrating workflows is necessary to break down silos and improve operational efficiency. Without this, teams struggle with duplicated efforts and incomplete insights. Additionally, the lack of a centralized data strategy can hinder collaboration among departments, as each team may rely on different tools and metrics to assess performance. This disjointed approach not only wastes resources but also limits the organization’s ability to leverage data for strategic decision-making. Implementing a unified data platform can help streamline processes and foster a culture of data-driven collaboration, ultimately enhancing overall productivity.
Data Quality, Lineage, and Trust
Ensuring data quality and traceability is particularly challenging with unstructured data. Unlike structured data, which benefits from strict validation rules, unstructured data can be noisy, incomplete, or inconsistent. Establishing data lineage—tracking the origin and transformations of data—is critical for compliance and trust.
Organizations must implement robust data governance frameworks and employ AI-driven data cleansing and enrichment techniques to maintain reliability and regulatory compliance. Furthermore, fostering a culture of data literacy among employees is essential. When team members understand the importance of data quality and are trained to recognize potential issues, they can contribute to maintaining high standards. Regular audits and assessments of data quality can also help organizations identify gaps and implement corrective measures proactively. By prioritizing data integrity, businesses can enhance their analytical capabilities and make more informed decisions based on trustworthy insights.
Best Practices for Unstructured Data Management
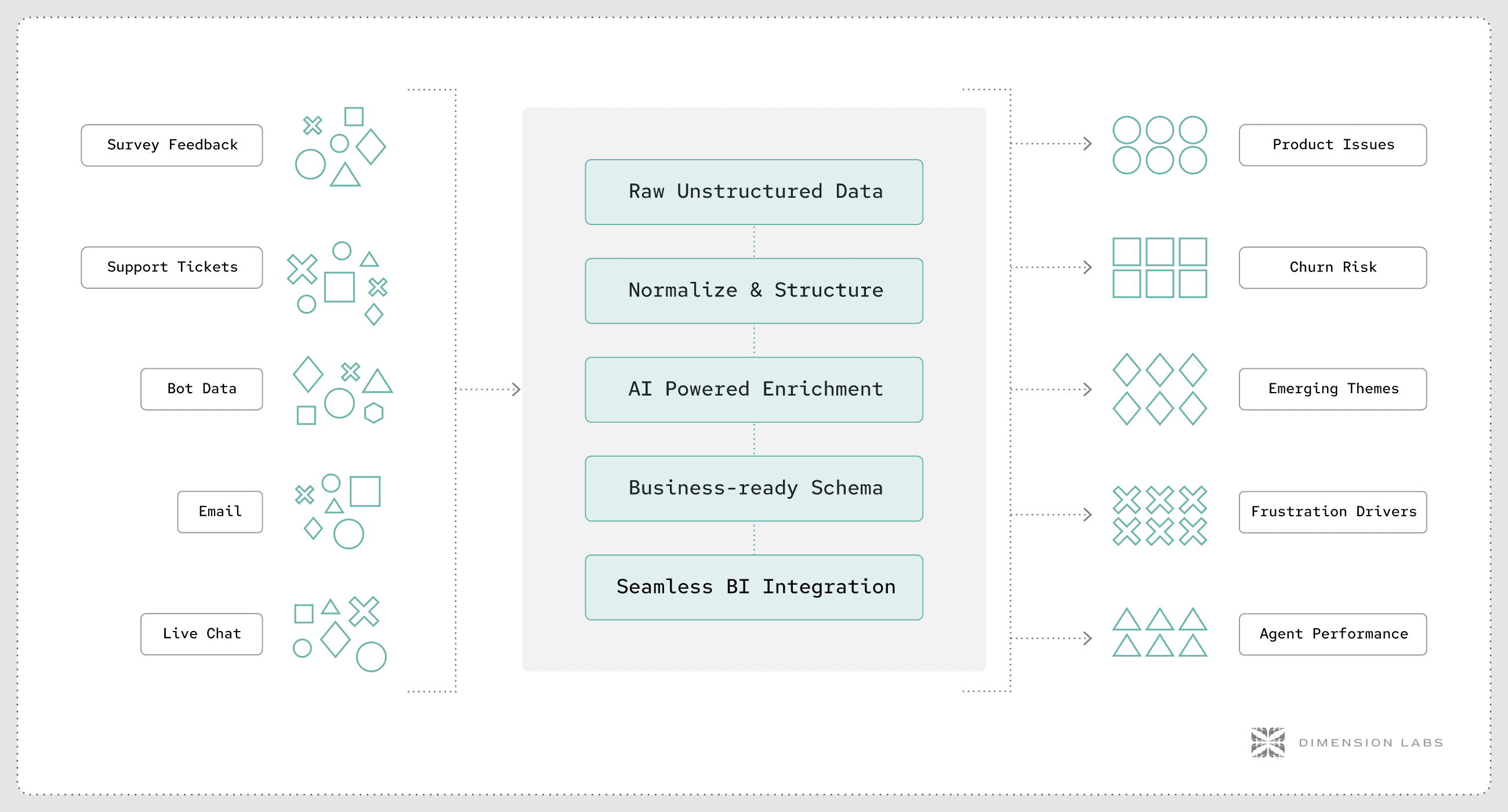
Discover and Catalog Every Source
Effective management starts with comprehensive discovery and cataloging of all unstructured data sources. This includes communication platforms, support tools, CRMs, and external data feeds.
Automated metadata extraction and classification tools help maintain an up-to-date inventory, enabling better governance and searchability. Cataloging also lays the foundation for subsequent data processing and analysis. Moreover, it is crucial to establish a governance framework that outlines roles and responsibilities for data stewardship. This ensures that the cataloging process is not a one-time effort but rather an ongoing initiative that adapts to new data sources as they emerge. Regular audits of the catalog can also help identify redundant or obsolete data, thereby streamlining the overall data management strategy.
Normalize and Clean Raw Logs
Raw unstructured data often requires normalization—converting data into a consistent format—and cleaning to remove noise, PII, and errors. This step is essential for making data usable and reliable for analytics.
Techniques such as text parsing, deduplication, and format standardization improve data quality and enable downstream processes like indexing and machine learning. Additionally, implementing automated cleaning pipelines can significantly reduce the manual effort involved in data preparation. By leveraging machine learning algorithms, organizations can identify patterns of errors and anomalies in the data, allowing for more intelligent cleaning processes that adapt over time. This proactive approach not only enhances data quality but also accelerates the analytics cycle, enabling quicker insights and more informed decision-making.
Enrich with AI and LLM Pipelines
Artificial intelligence (AI) and large language models (LLMs) play a transformative role in enriching unstructured data. They can automatically tag content, extract entities, detect sentiment, and summarize information.
These enrichments add semantic layers that make unstructured data more accessible and actionable. Integrating LLMs into data pipelines allows organizations to harness the power of natural language processing to derive insights from vast amounts of text data, such as customer feedback and conversations. This not only enhances the understanding of customer sentiment but also informs product development and marketing strategies, creating a more responsive and customer-centric business model.
Push BI-Ready Outputs Into Your Warehouse
After processing and enrichment, unstructured data should be transformed into business intelligence (BI)-ready formats and pushed into data warehouses or lakes. This integration enables analysts and data scientists to combine structured and unstructured data for holistic insights.
Providing clean, enriched datasets in familiar BI tools accelerates decision-making and maximizes the value extracted from unstructured data assets. Moreover, establishing a feedback loop where users can provide input on the usability of the BI outputs can lead to continuous improvement of data models and reporting formats. This iterative process not only enhances the relevance of the insights generated but also fosters a data-driven culture within the organization, empowering teams to rely on data for strategic initiatives.
A Modern Approach: The Unstructured Data ETL Layer
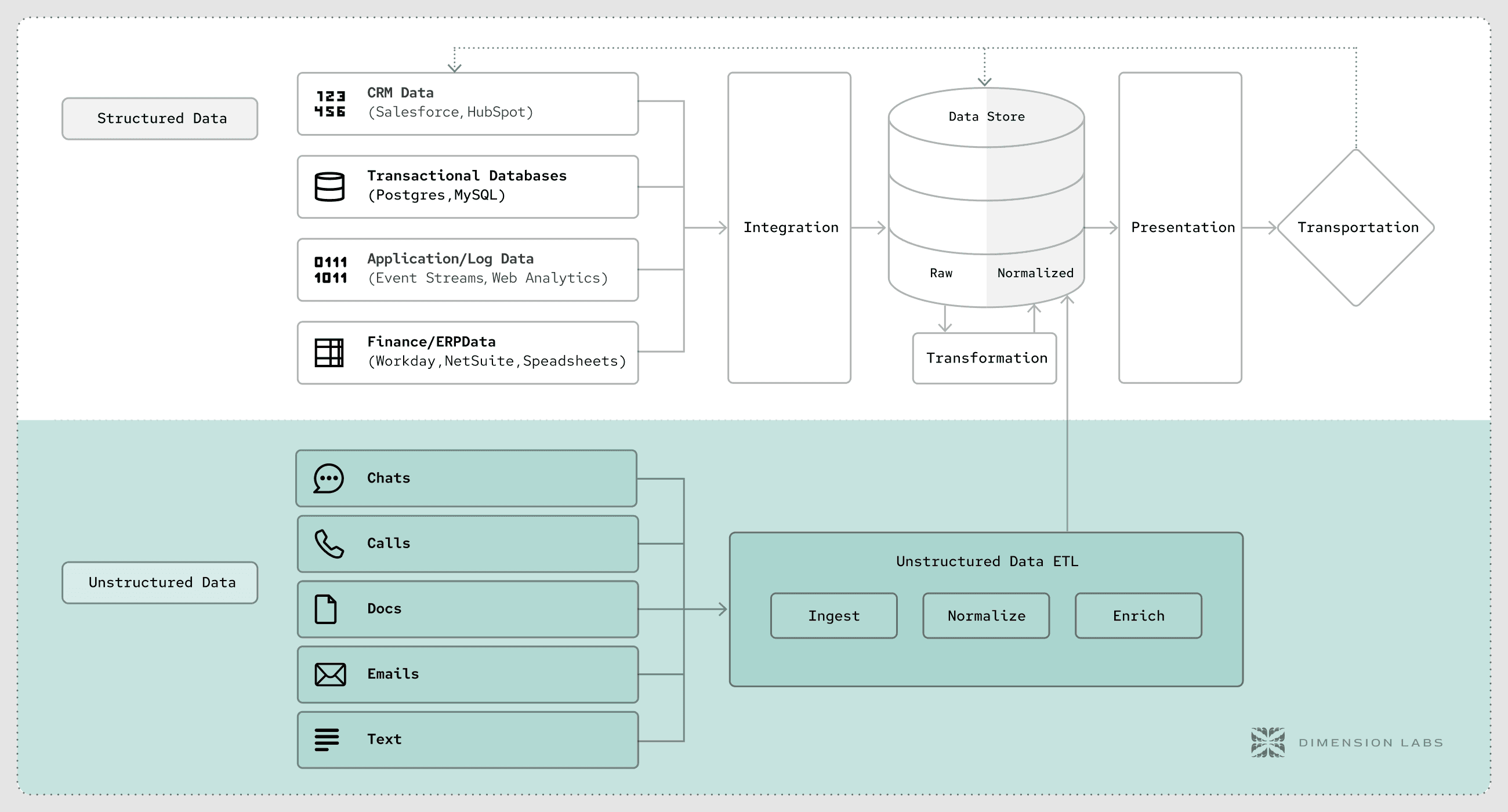
How It Fits Into the Modern Data Stack
The traditional Extract, Transform, Load (ETL) process has evolved to accommodate the complexities of unstructured data. The unstructured data ETL layer acts as an intermediary that ingests raw unstructured inputs, applies normalization, enrichment, and quality checks, then delivers curated outputs to downstream systems. This transformation is crucial as unstructured data can come from various sources, including chats, calls, emails, and documents, each with its unique challenges and requirements.
This layer integrates seamlessly with modern data stacks, supporting cloud-native architectures, real-time processing, and AI-driven analytics. It bridges the gap between raw unstructured data and actionable business intelligence. By leveraging advanced algorithms and machine learning techniques, organizations can derive meaningful insights from vast amounts of data that were previously considered too chaotic or inconsistent for traditional analytics.
Why Data Teams (Not Just CX) Should Own It
While customer experience (CX) teams often spearhead unstructured data initiatives due to their focus on calls, chats, and surveys, ownership should extend to broader data teams. Centralizing management under data engineering and analytics groups ensures consistent governance, scalability, and alignment with enterprise data strategies. This holistic approach enables organizations to maintain a single source of truth, reducing discrepancies and fostering collaboration across departments.
Data teams bring expertise in data pipelines, quality assurance, and integration, enabling more robust and reusable solutions that benefit multiple departments. By having a dedicated team that understands the intricacies of unstructured data, organizations can implement best practices for data management, ensuring that insights derived from customer interactions are not only accurate but also actionable.
The Rise of the Language Data Engineer
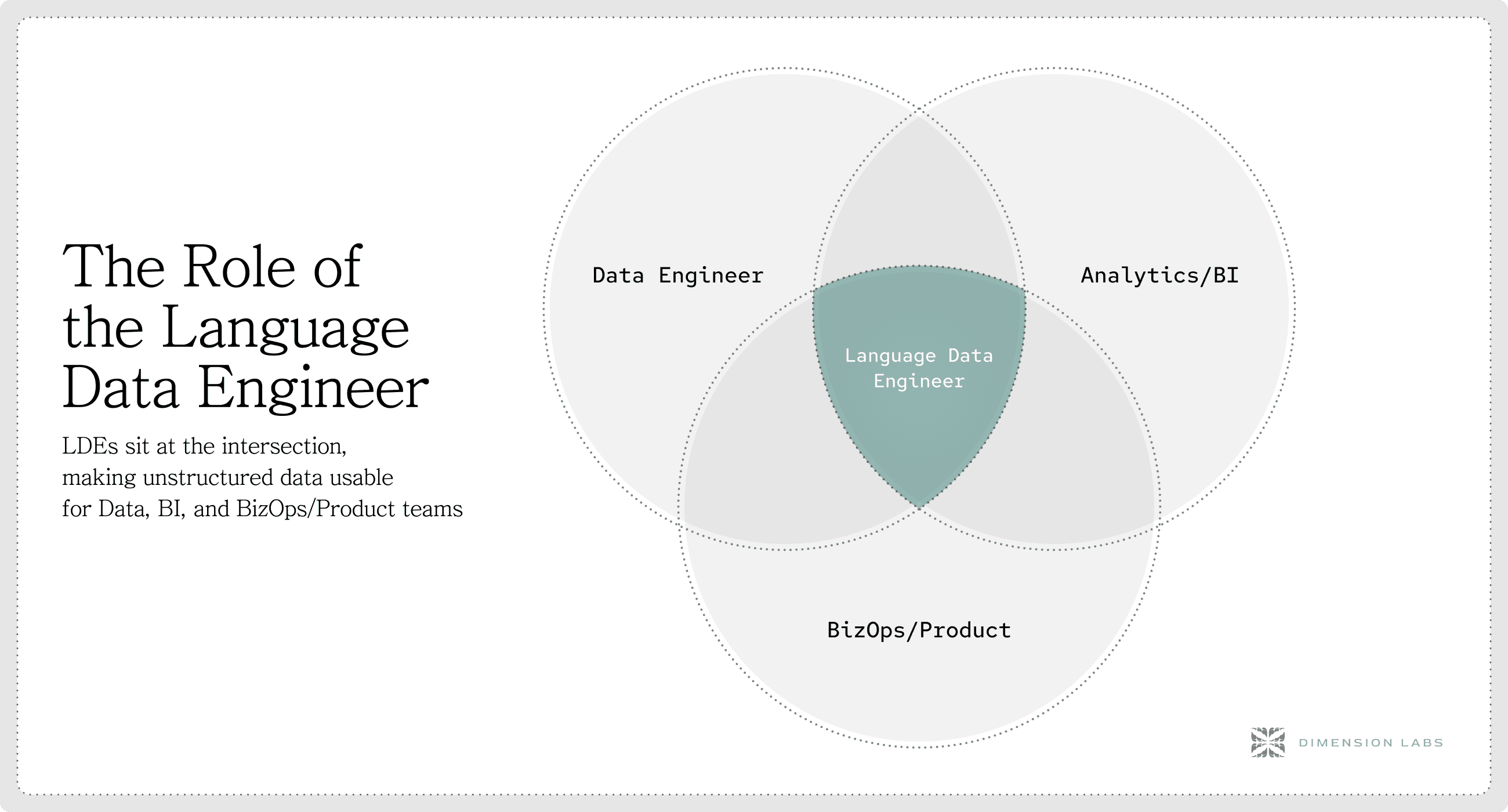
As unstructured data increasingly involves natural language processing and AI, a new role is emerging: the Language Data Engineer. These specialists design and maintain pipelines that process text, speech, and unstructured data, applying NLP models and AI techniques to unlock insights. The importance of this role cannot be overstated, as the ability to analyze and interpret human language is becoming a cornerstone of competitive advantage in many industries.
The Language Data Engineer blends skills from data engineering, computational linguistics, and AI, becoming vital in managing the growing complexity and volume of unstructured data in modern enterprises. This role not only requires technical proficiency but also a deep understanding of language nuances and proprietary business knowledge, enabling the extraction of richer insights from diverse data sources. With the unstructured data market projected to grow significantly, investing in such specialized talent and infrastructure is becoming a strategic priority.
Final thoughts
In closing, unstructured data is no longer a side note in enterprise analytics—it’s becoming the core driver of differentiation and innovation. The organizations that succeed in 2025 and beyond will be those that treat unstructured data not as a messy burden but as a strategic resource—one that, when properly cataloged, enriched, and integrated into the modern data stack, delivers insights impossible to capture from rows and columns alone. The challenge is real, but so is the opportunity: those who harness conversations, feedback, and free-form text at scale will not just understand their customers better—they’ll outpace their competitors.
If you’re interested in learning how to get started, reach out to Dimension Labs and explore how we can help you unlock the hidden value in your unstructured data.