
Why Building Your Own Unstructured Data ETL Pipeline Is Harder Than You Think
For the last decade, enterprises have built powerful data stacks for structured information. With modern tools like Fivetran, Snowflake, dbt, and Tableau, data teams can ingest, store, transform, and analyze structured data at scale. But when it comes to unstructured data — customer conversations, survey responses, emails, call transcripts — the playbook breaks down.
Naturally, many large companies assume: “We’ll just build it ourselves.” After all, they have world-class data engineering teams who’ve stitched together pipelines for everything from CRM data to IoT sensor streams. And while the logic is sound, the reality is far more complex as unstructured data is a different beast.
This article takes a hard, technical look at what it would actually take to build an Unstructured Data ETL pipeline in-house. We’ll walk through each stage of the pipeline, examine the tools and vendors you’d need, outline the technical and organizational challenges, and calculate the real costs in terms of time, resources, and money.
[Step 1] Ingestion and Integration: The First Roadblock
The very first step is simply getting the data out of silos and into your environment.
Unstructured data is spread across dozens of platforms:
Support tools like Zendesk, Intercom, Salesforce Service Cloud, Genesys.
Call centers powered by Twilio or Five9.
Survey platforms like Qualtrics, Medallia, SurveyMonkey.
Collaboration and email systems like Outlook, Gmail, or Slack.
Unlike structured SaaS APIs (CRM, finance, or HR tools), these systems expose inconsistent payloads, where even the definition of a “conversation” varies. Zendesk might split one customer interaction into multiple events, while Intercom treats the same interaction as a single thread.
What you’d have to build internally:
Dozens of custom API connectors that can ingest raw conversational payloads.
Logic to sessionize interactions (e.g., stitching 47 chat messages back into a coherent conversation).
Infrastructure to handle rate limits, retries, and schema drift whenever APIs change.
Available tools:
Fivetran, Airbyte, Stitch work well for structured data, but they’re brittle with conversation data. They’ll pull raw JSON blobs, but won’t sessionize or normalize them.
For call centers, custom jobs using AWS Lambda or Python scripts are often required.
For survey data, many companies fall back to manual batch exports into S3.
Challenges at this stage:
APIs lack consistency: every platform defines “sessions” differently, requiring heavy custom logic.
High fragility: schema drift, rate limits, and API changes mean ingestion pipelines constantly break.
Scale stress: handling millions of conversations demands infrastructure for retries, deduplication, and monitoring.
Resource drain: even before analysis, enterprises burn significant engineering time simply keeping ingestion alive.
The cost of this stage:
Expect at least 2–3 data engineers full time just to maintain ingestion pipelines.
Salary cost: $300k–500k/year.
Ongoing maintenance cost: high, since APIs change frequently.
Even before you clean or analyze the data, ingestion becomes a maintenance treadmill.

Closing thought: Without robust ingestion, the rest of the pipeline collapses. Enterprises quickly learn that “just pulling APIs” is far more brittle and expensive than expected, especially when conversation payloads don’t conform to standards. Every change upstream ripples into downstream disruption, forcing constant firefighting. And ingestion is only the beginning — even if you manage to wrangle these streams, the raw data that lands will be inconsistent, duplicative, and filled with noise. That leads directly into the next challenge: how do you clean, normalize, and prepare this messy language data for analysis?
[Step 2] Normalization and Cleaning: The Hidden Complexity
Once the data lands, the real work begins. Raw language data is messy and not analytics-ready.
Consider a single customer support transcript:
It might contain personally identifiable information (PII) like names, phone numbers, or credit card details.
Metadata such as timestamps, speaker roles, and conversation IDs may be missing or inconsistent.
Different vendors describe the same concept differently: Zendesk’s “ticket status” ≠ Salesforce’s “case status.”
What you’d need to build internally:
PII redaction pipelines to scrub sensitive data. Regex isn’t enough; you’d need entity recognition models.
Standardized metadata formats to unify “user_id,” “customer_id,” “account_id,” etc.
Cross-platform schema alignment so that “open tickets” and “active cases” map to a shared taxonomy.
Tools and vendors you could use:
spaCy + Presidio for entity recognition and PII redaction.
AWS Comprehend or GCP DLP for enterprise-grade data redaction.
Custom normalization scripts to map schema fields across vendors.
Challenges at this stage:
Even a 1% failure in PII redaction could create compliance risks under GDPR, HIPAA, or CCPA.
Schema drift means every new data source requires revisiting the normalization logic.
The cost of this stage:
At least 1 machine learning engineer dedicated to data cleaning and compliance.
Salary cost: $200k/year.
Additional compliance/legal overhead.
Without rigorous normalization, your enriched outputs won’t be trusted by business stakeholders.

Closing thought: This stage exposes a reality most teams underestimate: unstructured data isn’t just messy, it’s unruly. What looks like a transcript is actually dozens of half-formed fragments spread across systems, littered with sensitive information and schema inconsistencies. Every fix uncovers another exception. And without a clean, reliable foundation, no downstream enrichment or analysis can be trusted. Once you’ve solved for cleaning, the real heavy lift begins — enriching this language data into signals that business stakeholders can act on.
[Step 3] Enrichment and AI Labeling: Where the Hardest Problems Live
Now that you’ve handled ingestion, integration, and the necessary cleaning steps, the focus shifts to making sense of the text itself. The single biggest challenge in building an Unstructured Data ETL pipeline is turning free-text into structured signals.
This step requires enriching every customer conversation with AI-driven dimensions, such as:
Sentiment and tone (positive, neutral, negative).
Intent classification (e.g., billing issue, cancellation request, product feedback).
Root cause labeling (underlying drivers of customer frustration).
Predictive metrics (likelihood of churn, escalation risk).
What you’d need to build internally:
Fine-tuned models or LLM pipelines to classify and enrich conversations.
Vector embeddings for semantic similarity search.
Prompt orchestration frameworks to chain together LLM calls for accuracy.
Validation pipelines to catch hallucinations and misclassifications.
Available tools:
OpenAI, Anthropic, Cohere APIs for LLM inference.
Vector databases like Pinecone, Weaviate, or Milvus.
LangChain or DSPy for orchestration.
Challenges:
LLMs hallucinate → You need fallback strategies and human validation loops.
Latency and cost scale linearly with volume. Running enrichment over 100M rows/year can cost hundreds of thousands in API fees.
Domain adaptation is critical: a telco’s “drop” is not the same as a SaaS “drop.”
The cost of this stage:
2–3 ML engineers + 1 prompt engineer.
Salary cost: $500k–700k/year.
LLM API/compute cost: $200k–500k/year, depending on scale.
This stage is where most DIY projects stall out. It’s not just about running sentiment analysis; it’s about building a full data enrichment engine that can be trusted for business-critical workflows.

Closing thought: Here, the effort multiplies. Running a single sentiment model isn’t enough — teams need a layered AI stack to capture intent, emotion, effort, root cause, and predictive metrics. Each of these dimensions requires orchestration, validation, and adaptation to domain context. And the scale challenge is massive: millions of rows, each requiring multiple enrichment passes. At this point, internal teams often realize they’ve recreated half a product company just to produce labels. And yet, labels alone don’t drive business value — unless they’re mapped into schemas that mirror how the business actually thinks. That takes us into the next phase: dimensional mapping.
[Step 4] Schema and Dimensional Mapping: Making Data Business-Ready
Even if enrichment works, the data is still unusable unless it’s structured in a way that makes sense for the business.
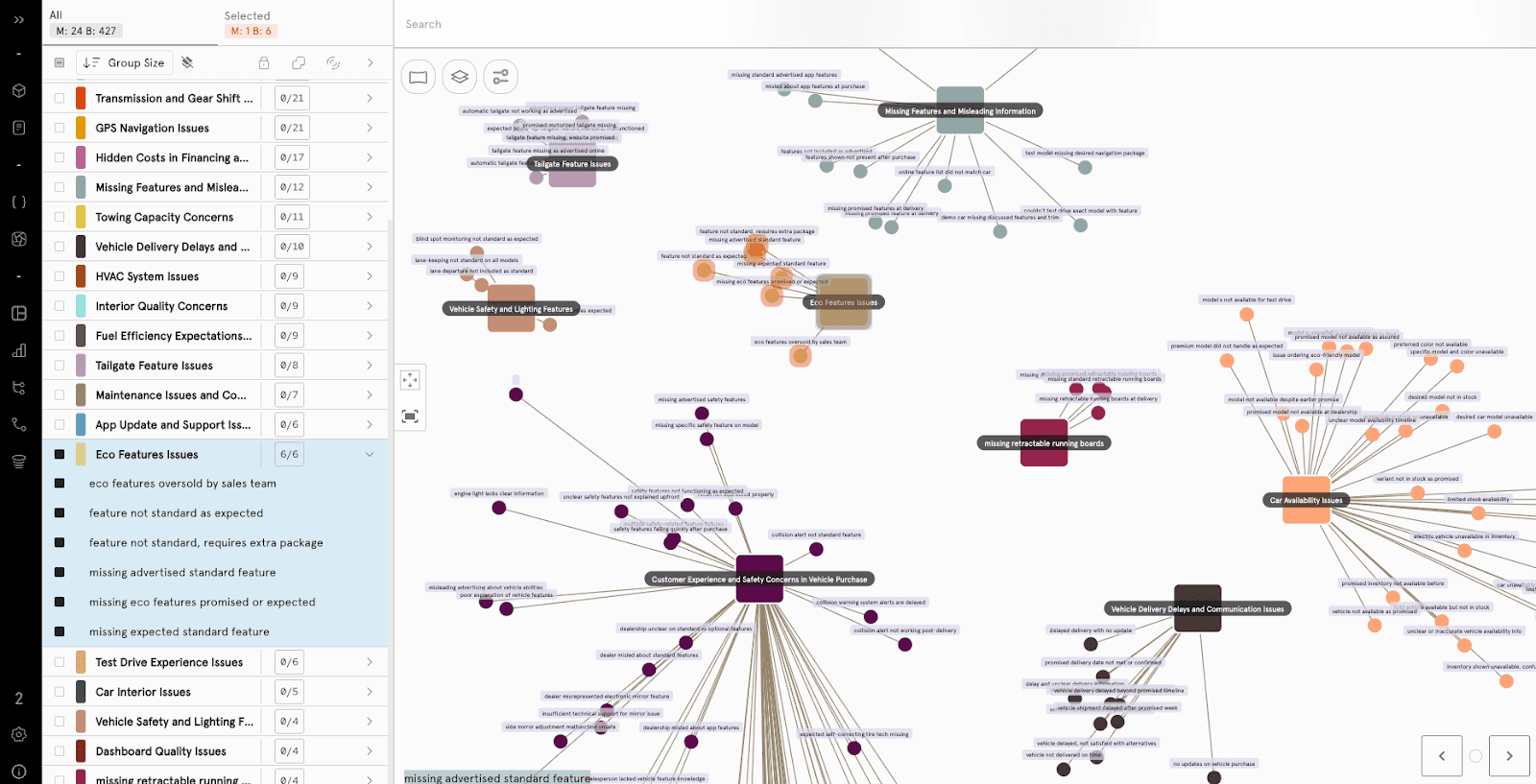
Enter schema and dimensional mapping. This is where enriched signals are organized into governed taxonomies. A few common examples:
Categories: Billing, Onboarding, Feature Requests, Bugs.
Metrics: Emotion, Customer Effort Score, Predicted CSAT.
Business dimensions: Customer Segment, Geography, Product Line.
What you’d need to build internally:
A dimensional model for unstructured data (akin to dbt models for structured data).
Cluster merging pipelines to consolidate overlapping categories.
Version control for schemas as taxonomies evolve.
Available tools:
dbt can help with transformations, but won’t create the schema for you.
Collibra, Alation provide governance, but not enrichment.
Challenges:
Every company has its own taxonomy → no off-the-shelf schema fits all.
Categories drift as products and markets evolve.
The cost of this stage:
1 analytics engineer + 1 business analyst.
Salary cost: $150k–200k/year.
This stage is where “dark data” becomes BI-ready tables. Without it, you’re just creating noise.

Closing thought: This stage separates toy projects from enterprise-ready systems. Without dimensional mapping, you don’t have business intelligence — you just have enriched noise. Taxonomies have to be designed, merged, versioned, and kept aligned with how the business evolves. It’s one thing to know that “wait time too long” and “long queue lines” are related; it’s another to consolidate them into a governed field like Operational Delay. Without that mapping, BI teams can’t query or join unstructured data with the rest of the warehouse. And once the schema is locked, you face the next hurdle: getting these insights into the hands of end users through outputs and activation.
[Step 5] Output and Activation: Delivering Insights to the Business
Finally, the data has to make its way into the tools business users rely on every day.
What you’d need to do:
Push structured outputs into Snowflake, BigQuery, or Databricks.
Create dashboards in Tableau, Power BI, or Looker.
Build reverse ETL pipelines to push insights back into Salesforce, HubSpot, or CX platforms.
Available tools:
Hightouch, Census for reverse ETL.
Tableau, Looker, Power BI, Hex for dashboards.
Challenges:
Linking enriched insights back to raw transcripts for explainability.
Scaling dashboards to handle tens of millions of rows.
Ensuring self-service access across departments (CX, product, operations, executives).
The cost of this stage:
1 BI engineer + ongoing data team support.
Salary cost: $150k–200k/year.
Without activation, all the work upstream never impacts decision-making.

Closing thought: Even with clean, enriched, schema-mapped data, the pipeline is incomplete if insights never reach decision-makers. The activation step is where value is realized. Without reliable output to BI tools and reverse ETL back into operational systems, unstructured data remains stranded. Worse, the lack of explainability (linking insights back to raw transcripts) can erode trust. This is where the promise of an “unstructured data ETL” pipeline either materializes or collapses. And even if you activate successfully, you’re still not done — because every stage upstream drifts, models decay, and compliance obligations evolve. Which brings us to the most relentless part of all: governance and maintenance.
[Step 6] Governance, Compliance, and Ongoing Maintenance
Even if you’ve built all of the above, the work is never done.
What you’d need to maintain:
Pipeline observability: Detecting data loss, latency spikes, or schema drift.
Compliance monitoring: GDPR, HIPAA, and CCPA obligations.
Model retraining: Ensuring AI enrichment remains accurate over time.
Available tools:
Monte Carlo, Bigeye, Databand for observability.
AWS GuardDuty, private VPCs for security.
Challenges:
Every new source or schema change requires engineering effort.
Costs rise as data volume grows.
Business users lose trust quickly if accuracy slips.
The cost of this stage:
1 DataOps/SRE engineer.
Salary cost: $200k–400k/year.
This becomes an infinite treadmill of maintenance.

Closing thought: At this point, most enterprises have sunk millions of dollars and years of engineering time into their pipeline — only to discover that the real cost is ongoing. Pipelines drift, APIs break, compliance frameworks shift, and models lose accuracy. Every win upstream creates maintenance obligations downstream. This is the treadmill that never ends. And for many organizations, it’s the moment of realization: building unstructured data ETL in-house isn’t just difficult, it’s a distraction from the business of running the business. That’s why more and more enterprises are choosing to partner with specialized platforms like Dimension Labs — because the alternative isn’t just expensive, it’s unsustainable.
The True Cost of DIY
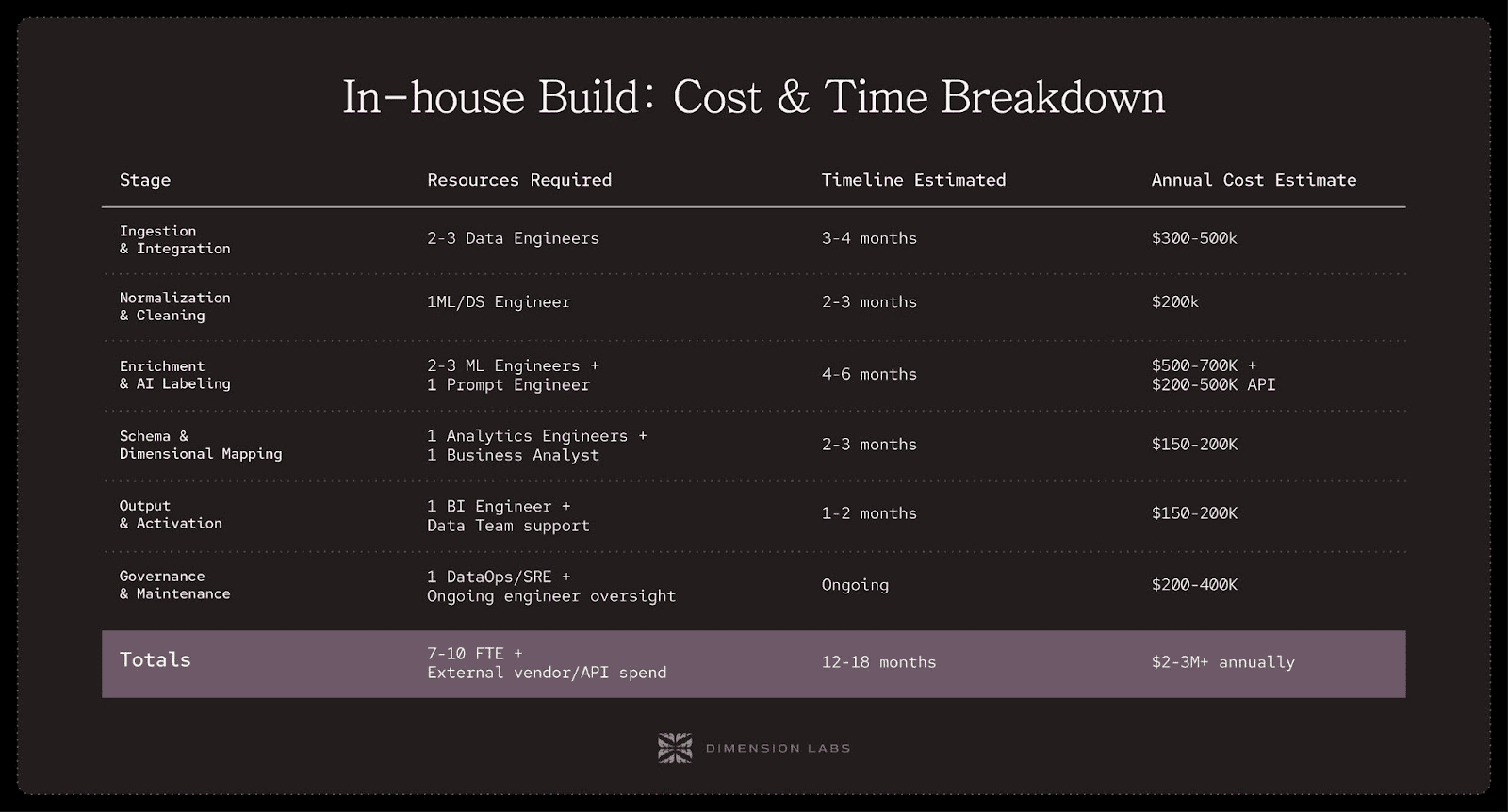
Let’s add it all up:
Team size: 7–10 full-time engineers.
Annual salary cost: $1.5M–2M+.
Vendor/API/infra cost: $500k–1M+.
Timeline to MVP: 12–18 months.
Ongoing annual run-rate: $2M–3M+.
And that’s just to reach parity with what platforms like Dimension Labs already provide.
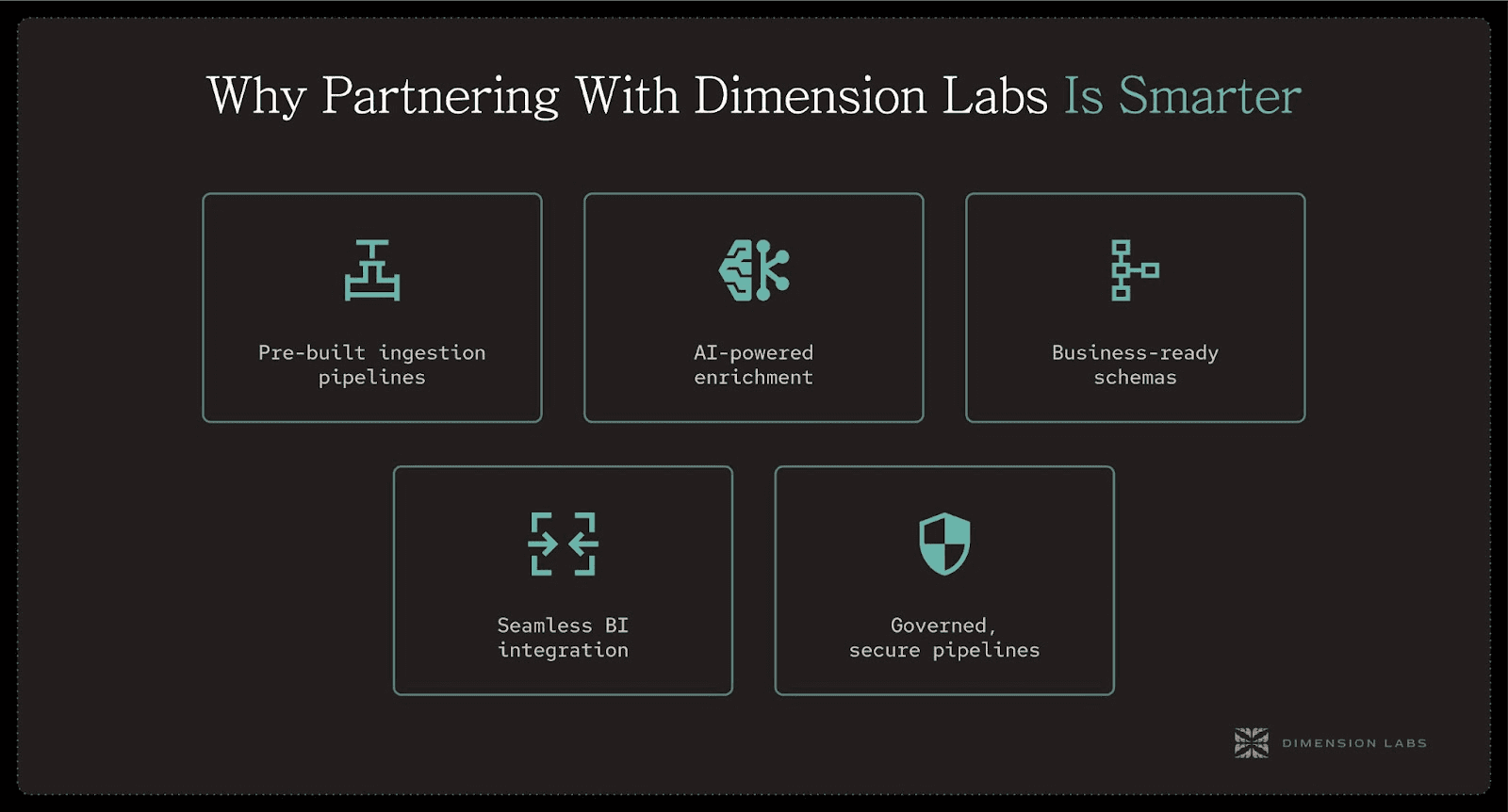
Why Partnering With Dimension Labs Is Smarter
Dimension Labs exists because building all of the above internally is not just difficult — it’s prohibitively expensive and time-consuming. We help you avoid undifferentiated heavy lifting, freeing your resources from infrastructure builds and redirecting them to innovation.
We provide:
Pre-built ingestion pipelines for major conversational and survey platforms.
AI-powered enrichment with multi-model orchestration for accuracy.
Business-ready schemas out of the box, tuned to enterprise needs.
Seamless BI integration into Snowflake, Databricks, Tableau, Power BI, or Hex.
Governed, secure pipelines compliant with GDPR, HIPAA, and enterprise requirements.
Instead of spending 18 months and $3M building pipelines, you can be live in weeks — at a fraction of the cost.
Closing Thought
The modern data stack unlocked the value of structured data. The next frontier is unstructured data. Enterprises that figure out how to operationalize it will leap ahead in customer understanding, product strategy, and competitive edge.
You can try to build it yourself. But the cost, fragility, and time-to-value will cripple the effort.
The smarter path is clear: partner with a trusted vendor who has already solved the problem.
At Dimension Labs, we make unstructured language data a first-class citizen in the modern data stack — so your data teams can stop building pipelines and start delivering impact.